---
title: "AuroraGPT: Training Foundation Models on Supercomputers"
description: "A deep dive into the challenges and solutions for training large-scale AI models on supercomputing infrastructure."
categories: ["AI", "Machine Learning", "Supercomputing"]
location: "Argonne National Laboratory"
location-logo: "/assets/anl_logos/anl-color.svg"
location-url:
date: 2025-12-16
date-modified: last-modified
image: ./assets/thumbnail.png
lightbox: auto
editor:
render-on-save: true
twitter-card:
image: ./assets/thumbnail.png
site: "saforem2"
creator: "saforem2"
title: "Training Foundation Models on Supercomputers"
description: "Presented at Argonne National Laboratory"
open-graph:
title: "Training Foundation Models on Supercomputers"
description: "Presented at Argonne National Laboratory"
image: "./assets/thumbnail.png"
citation:
author: Sam Foreman
type: speech
url: https://samforeman.me/talks/2025/12/16/slides.html
format:
html:
image: "assets/thumbnail.png"
revealjs:
image: "assets/thumbnail.png"
shift-heading-level-by: -1
logo: "/assets/anl-black.svg"
slide-url: https://samforeman.me/talks/2025/12/16/slides.html
footer: "[samforeman.me/talks/2025/12/16/slides](https://samforeman.me/talks/2025/12/16/slides)"
template-partials:
- "title-slide.html"
title-slide-attributes:
data-background-color: "#E9F3DC"
mermaid-format: "svg"
mermaid:
theme: default
layout: dagre
useMaxWidth: true
timeline:
disableMulticolor: true
gfm: default
---
### 🧰 AuroraGPT: Toolbox
- **Datasets and data pipelines**
(how do we deal with scientific data?)
- **Software infrastructure and workflows**
(scalable, robust, extensible)
- **Evaluation of state-of-the-art LLM Models**
(how do they perform on scientific tasks?)
<!-- ::: {.callout-tip icon=false title='✨ New!' collapse="false" style="text-align: left!important; background-color:rgba(131,131,131,0.05)!important; border: 1px solid rgba(131,131,131,0.0); width: calc(100% - 2pt)!important; opacity:100%;"} -->
::: {.flex-container style="gap: 5pt; margin-block-end: 5pt;"}
::: {.callout-tip icon=false title="🍋 ezpz"}
{{< fa brands github >}} [saforem2/ezpz](https://github.com/saforem2/ezpz)
[Write once, run anywhere]{.dim-text}
:::
::: {.callout-note icon=false title="🚂 Training"}
{{< fa brands github >}} [argonne-lcf/Megatron-DeepSpeed](https://github.com/argonne-lcf/Megatron-DeepSpeed)
[For the largest of large language models]{.dim-text}
:::
::: {.callout-important icon=false title="🏃♂️ Running"}
{{< fa brands github >}} [argonne-lcf/inference-endpoints](https://github.com/argonne-lcf/inference-endpoints)
[Inference endpoints for LLMs, hosted @ ALCF]{.dim-text}
:::
:::
### 👥 Team Leads {.smaller background-color="white"}
::: {style="font-size: 100%;"}
::: {.flex-container style="text-align: center; align-items: center;"}
**Planning**
![Rick Stevens[^lead]](/assets/team/rick-stevens.png){height="75pt"}
{height="75pt"}
{height="75pt"}
{height="75pt"}
{height="75pt"}
{height="75pt"}
:::
::: {.flex-container style="text-align: center;"}
::: {.col}
**Data**
{height="75pt"}
{height="75pt"}
:::
::: {.col}
**Training**
{height="75pt"}
![[Sam Foreman]{style="color: #ff1a8f; background-color: oklch(from #ff1a8f calc(l * 1.15) c h / 0.1); font-weight: 500;"}](/assets/team/sam-foreman.png){height="75pt"}
:::
::: {.col}
**Evaluation**
{height="75pt"}
{height="75pt"}
{height="75pt"}
:::
::: {.col}
**Post**
{height="75pt"}
{height="75pt"}
:::
::: {.col}
**Inference**
{height="75pt"}
:::
::: {.col}
**Comms**
{height="75pt"}
{height="75pt"}
:::
::: {.col}
**Distribution**
{height="75pt"}
:::
:::
:::
[^lead]: Lead
### 🤝 Teams {auto-animate=true background-color="white"}
::: {.flex-container}
::: {.column}
- **Planning**
- **Data Prep**
- Accumulate 20+ T tokens of high-quality scientific text and structured data
- [**Models / Training**]{style="background: oklch(from #ff1a8f calc(l * 1.15) c h / 0.1); border: 1px solid #ff1a8f; border-radius: 0.25px;"}[^me]
- Train (entirely from scratch) a series of models on publicly available data
- **Evaluation**
- Skills, trustworthiness, safety, robustness, privacy, machine ethics
[^me]: Co-led by: Venkat Vishwanath, Sam Foreman
:::
::: {.column}
- **Post-Training**
- Fine-tuning, alignment
- **Inference**
- Model serving, API development / public-facing web services
- **Distribution**
- Licensing, generating and distributing artifacts for public consumption
- **Communication**
:::
:::
## 🏋️ Challenges
This is _incredibly_ difficult in practice, due in part to:
- Brand new {hardware, architecture, software}
- Lack of native support in existing frameworks (though getting better!)
- General system stability
\+10k Nodes $\left(\times \frac{12\,\,\mathrm{XPU}}{1\,\,\mathrm{Node}}\right)\Rightarrow$ \+**100k** XPUs
- network performance
- file system stability (impacted by _other users_ !)
- _many_ unexpected difficulties occur at increasingly large scales
- Combinatorial explosion of possible configurations and experiments
- {hyperparameters, architectures, tokenizers, learning rates, ...}
### 💾 AuroraGPT: Training
- To train a fixed model on trillions of tokens requires:
1. **Aggregating** data from multiple different _corpora_
(e.g. ArXiv, Reddit, StackExchange, GitHub, Wikipedia, etc.)
1. **Sampling** _each training batch_ according to a fixed distribution
across corpora
1. **Building** indices that map batches of tokens into these files
(indexing)
::: {.red-card}
The original implementation was _slow_:
- Designed to run _serially_ on a **single device**
- **Major bottleneck** when debugging data pipeline at scale
:::
### 🍹 AuroraGPT: Blending Data, Efficiently
::: {.flex-container style="padding: 10pt; justify-content: space-around; align-items: flex-start;"}
::: {.column style="width:25%;"}
- 🐢 Original implementation:
- **Slow** (serial, single device)
- [\~ 1 hr]{.dim-text}/2T tokens
- 🐇 New implementation:
- **Fast!** (distributed, asynchronous)
- [\~ **2 min**]{style="color:#2296F3;"}/2T tokens
(**30x** faster !!)
:::
::: {.column}
{#fig-data-processing .r-stretch}
:::
:::
### 📉 Training AuroraGPT-7B on 2T Tokens
::: {.content-visible when-format="html" unless-format="revealjs"}
::: {#fig-loss-curve}
{.width="90%" style="margin-left:auto;margin-right:auto;"}
Loss curve during training on 2T tokens.
:::
:::
::: {.content-visible when-format="revealjs"}
::: {#fig-loss-curve}
{width="90%" style="margin-left:auto;margin-right:auto;"}
Train (grey) and validation (blue) loss vs number of consumed training tokens
for AuroraGPT-7B on 64 nodes of Aurora.
:::
:::
### 📉 Training AuroraGPT-2B on 7T Tokens
::: {#fig-auroragpt-2b}
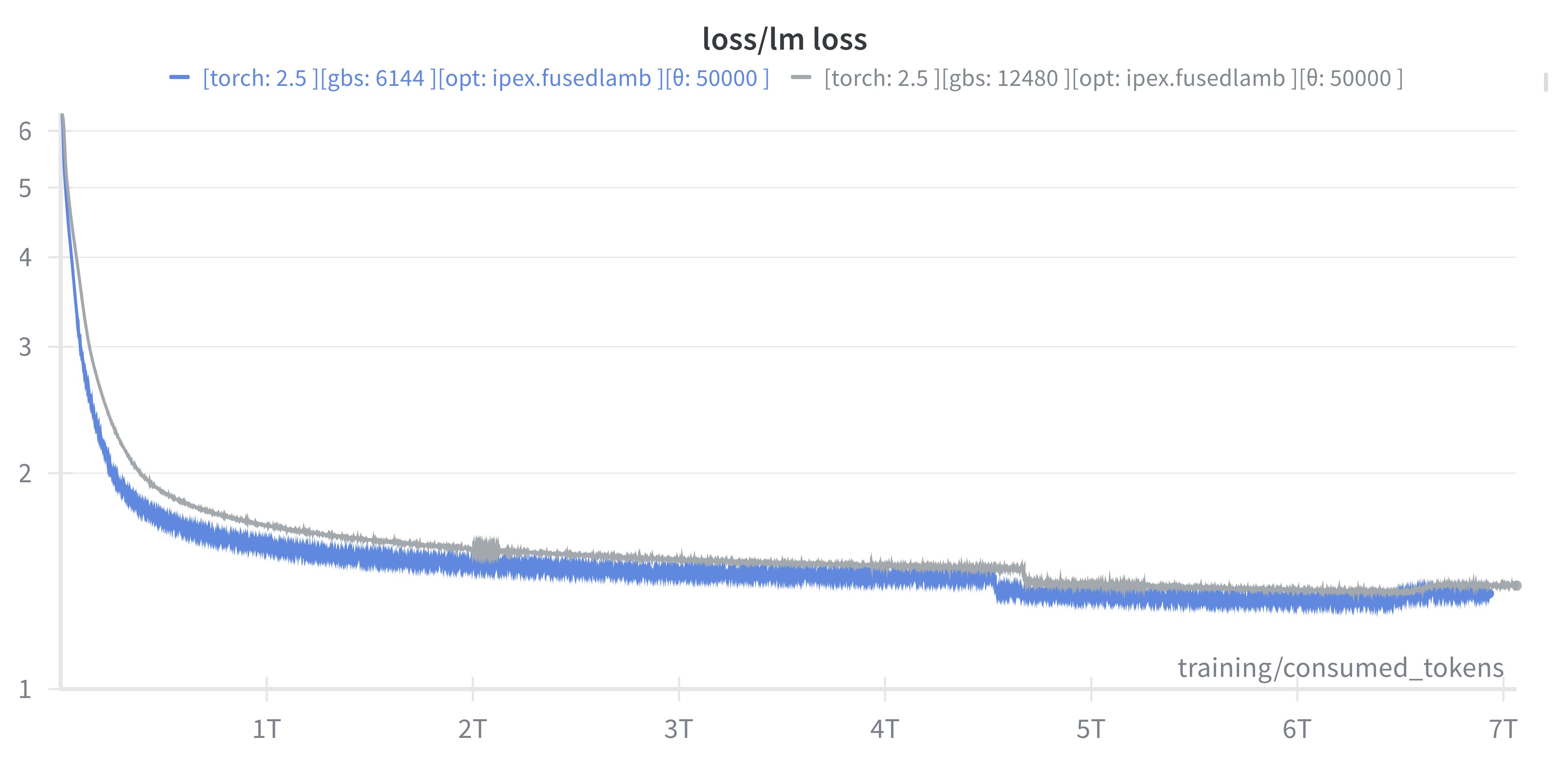
(**new**) Loss vs number of consumed training tokens for AuroraGPT-2B on 256
(blue) and 520 nodes (grey) of Aurora. Both runs show stability through 7T
tokens.
:::
### ✨ Features
{{< fa brands github >}} [argonne-lcf/Megatron-DeepSpeed](https://github.com/argonne-lcf/Megatron-DeepSpeed)
- 🕸️ **Parallelism**:
- {data, tensor, pipeline, sequence, ...}
- ♻️ **Checkpoint Converters**:
- Megatron ⇄ 🤗 HF ⇄ ZeRO ⇄ Universal
- 🔀 **DeepSpeed Integration**:
- ZeRO Offloading
- Activation checkpointing
- AutoTP (*WIP*)
- ability to leverage features from DeepSpeed community
### ✨ Features (even more!)
- 🧗 **Optimizers**[^marieme]:
- Support for *many* different optimizers:
- Distributed Shampoo, Muon, Adopt, Sophia, Lamb, GaLORE, ScheduleFree, ...
- See
[full list](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/e3b0398d2f2d3f8ec543e99373ca14bd18a1e4f8/megatron/arguments.py#L1477-L1502)
- Large batch training
- 📊 **Experiment Tracking**:
- Automatic experiment and metric tracking with Weights \& Biases
[^marieme]: Implemented by Marieme Ngom
## 🧬 MProt-DPO {style="width:100%;"}
- [Finalist]{.highlight-green}: SC'24 [ACM Gordon Bell Prize](https://sc24.supercomputing.org/2024/10/presenting-the-finalists-for-the-2024-gordon-bell-prize/)
- [MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows with Direct Preference Optimization](https://www.researchgate.net/profile/Carla-Mann-3/publication/387390653_MProt-DPO_Breaking_the_ExaFLOPS_Barrier_for_Multimodal_Protein_Design_Workflows_with_Direct_Preference_Optimization/links/67a0f736645ef274a46243f1/MProt-DPO-Breaking-the-ExaFLOPS-Barrier-for-Multimodal-Protein-Design-Workflows-with-Direct-Preference-Optimization.pdf) (@mprot-dpo2024)
- One of the first protein design toolkits that integrates:
- Text, (protein/gene) sequence, structure/conformational sampling modalities
to build aligned representations for protein sequence-function mapping
### 🧬 Scaling Results (2024) {.smaller}
::: {.columns}
::: {.column style="width:70%;"}
::: {.flex-container style="align-items: center; text-align: center; margin-left: auto; margin-right: auto;"}
::: {#fig-mprot-3p5B-scaling0}
{width=100% style="margin:0; padding-unset;"}
Scaling results for `3.5B` model across ~38,400 GPUs
:::
:::
:::
::: {.column style="width:30%;"}
- ~ [4 EFLOPS]{.highlight-blue} @ Aurora
- 38,400 XPUs
= 3200 \[node\] x 12 \[XPU / node\]
- 🎖️ [Gordon Bell Finalist](https://sc24.supercomputing.org/2024/10/presenting-the-finalists-for-the-2024-gordon-bell-prize/):
- [MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows](https://dl.acm.org/doi/10.1109/SC41406.2024.00013) (@mprot-dpo2024)
:::
:::
::: notes
This novel work presents a scalable, multimodal workflow for protein design
that trains an LLM to generate protein sequences, computationally evaluates the
generated sequences, and then exploits them to fine-tune the model.
Direct Preference Optimization steers the LLM toward the generation of
preferred sequences, and enhanced workflow technology enables its efficient
execution. A 3.5B and a 7B model demonstrate scalability and exceptional mixed
precision performance of the full workflow on ALPS, Aurora, Frontier, Leonardo
and PDX.
:::
### 🧬 MProt-DPO: Scaling Results {.smaller}
::: {.flex-container}
::: {.column #fig-mprot-3p5B-scaling}

`3.5B` model
:::
::: {.column #fig-mprot-7B-scaling}

`7B` model
:::
:::
### 🚂 Loooooooooong Sequence Lengths {.smaller style="width: 100%;"}
::: {.flex-container style="align-items: center; justify-content: center;"}
{style="height:50pt; margin: unset; padding: 0"}
[{{< iconify ic baseline-plus >}}]{.dim-text style="font-size: 2.0em;"}
{style="height:50pt; margin: unset; padding: 0;"}
:::
- Working with
[{{< fa brands microsoft >}} Microsoft/DeepSpeed](https://github.com/microsoft/DeepSpeed)
team to enable longer sequence lengths (context windows) for LLMs
- See my [blog post](https://samforeman.me/posts/auroragpt/long-sequences/) for additional details
::: {#fig-long-seq}
::: {.flex-container}


:::
Maximum (achievable) `SEQ_LEN` for both `25B` and `33B` models (See: @song2023ds4sci)
:::
::: aside
[{{< fa brands github >}} `scaling4science`](https://github.com/saforem2/scaling4science)
[{{< fa brands github >}} `Megatron-DS-Benchmarking`](https://github.com/saforem2/Megatron-DS-Benchmarking)
:::
## 🌎 AERIS (2025)
::: {.content-visible unless-format="revealjs"}
::: {.flex-container}
::: {.flex-child style="width:50%;"}
](/assets/aeris/team.png){#fig-arxiv}
:::
::: {.flex-child style="width:43.6%;"}

:::
:::
:::
::: {.content-visible when-format="revealjs"}
::: {.flex-container}
::: {.column style="width:50%;"}
](/assets/aeris/team.png){#fig-arxiv}
:::
::: {.column style="width:43.6%;"}
![Pixel-level Swin diffusion transformer in sizes from \[1--80\]B](/assets/aeris/aeris.svg){#fig-aeris-cover}
:::
:::
:::
::: notes
> We demonstrate a significant advancement in AI weather
> and climate modeling with AERIS by efficient scaling of
> window-based transformer models. We have performed global
> medium-range forecasts with performance competitive with
> GenCast and surpassing the IFS ENS model, with longer, 90-
> day rollouts showing our ability to learn atmospheric dynamics
> on seasonal scales without collapsing, becoming the first
> diffusion-based model that can work across forecast scales
> from 6 hours all the way to 3 months with remarkably accurate
> out of distribution predictions of extreme events.
:::
### 👀 High-Level Overview of AERIS {.smaller}
::: {.flex-container}
::: {#fig-rollout}
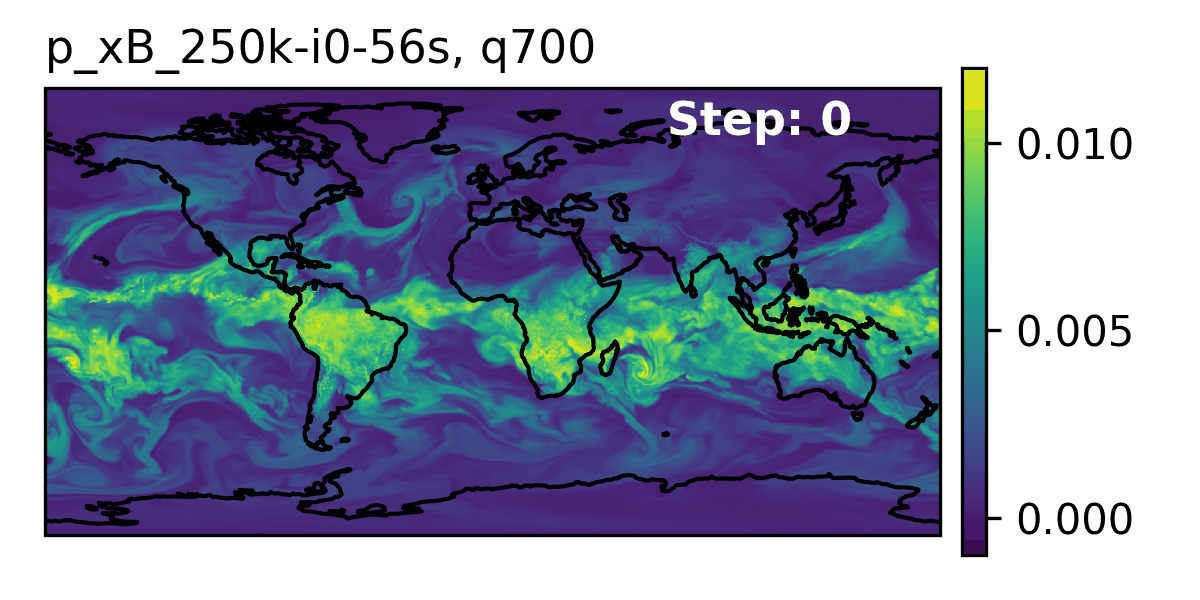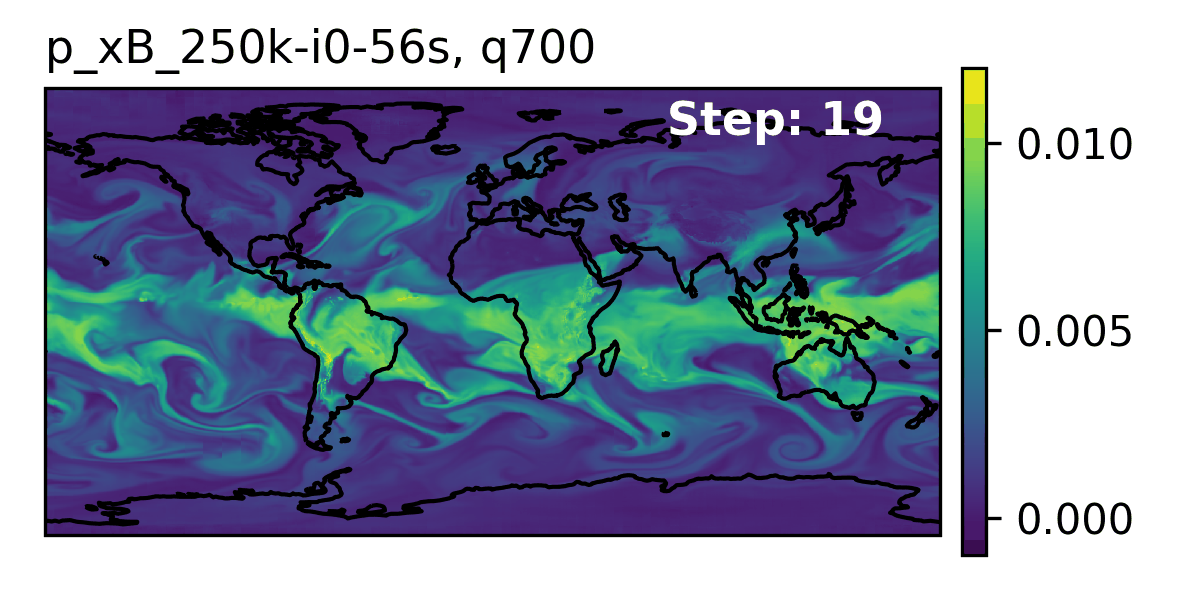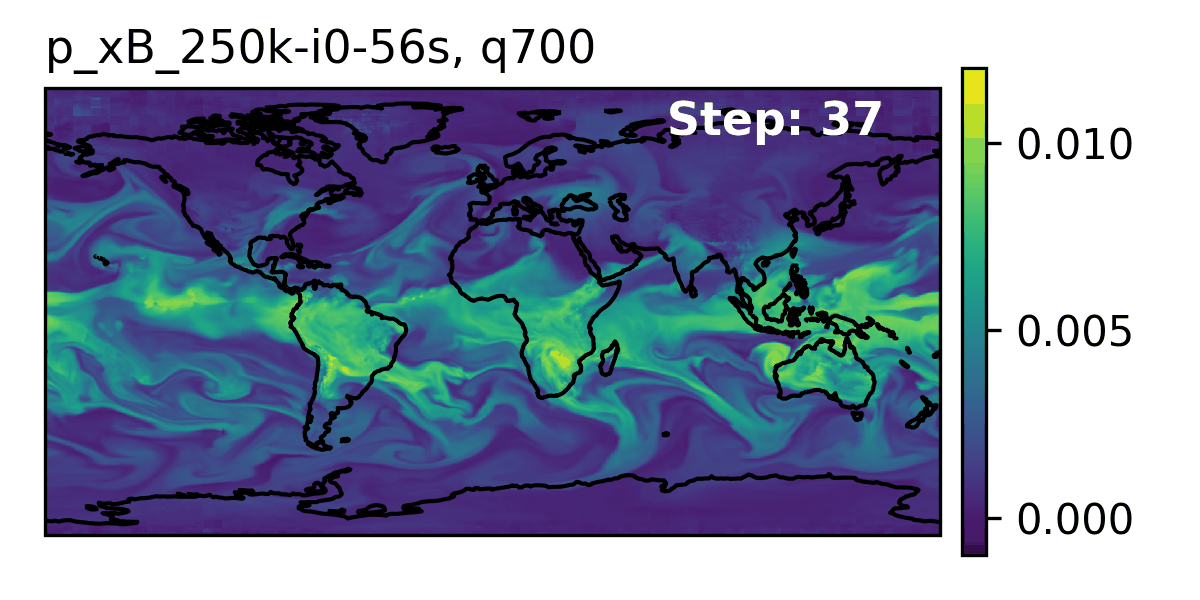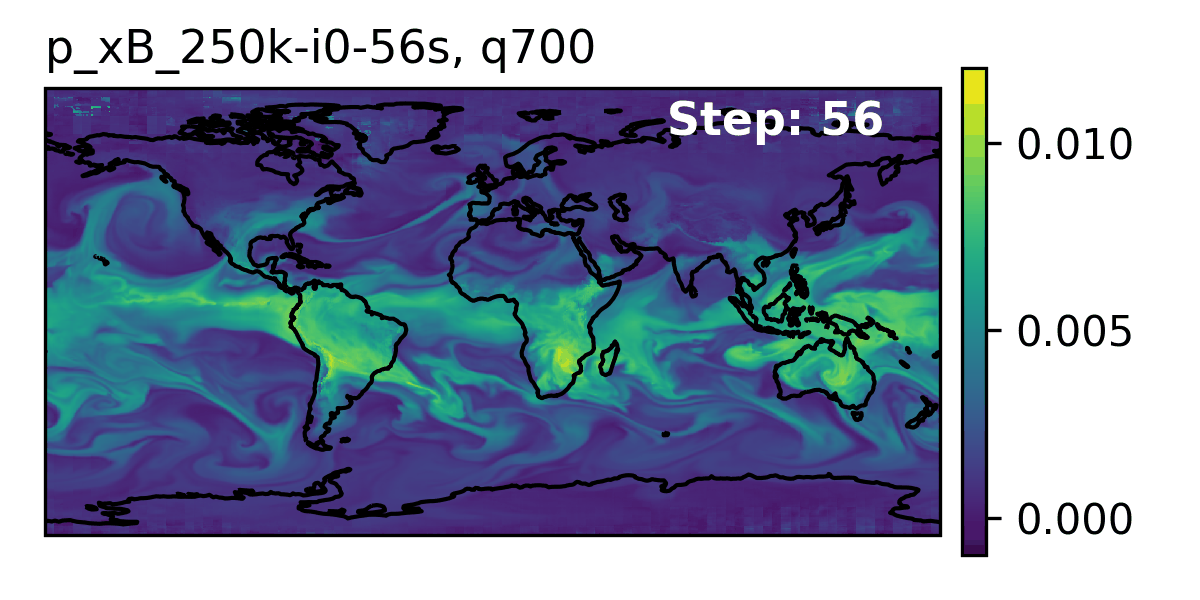
Rollout of AERIS model, specific humidity at 700m.
:::
::: {#tbl-aeris}
| Property | Description |
| -----------------: | :---------------- |
| Domain | Global |
| Resolution | 0.25° \& 1.4° |
| Training Data | ERA5 (1979--2018) |
| Model Architecture | Swin Transformer |
| Speedup[^pde] | O(10k--100k) |
: Overview of AERIS model and training setup {.responsive .striped .hover}
:::
:::
[^pde]: Relative to PDE-based models, e.g.: [GFS](https://www.ncdc.noaa.gov/data-access/model-data/model-datasets/global-forcast-system-gfs)
### ➕ Contributions
::: {.flex-container}
::: {.callout-caution icon=false title="☔ AERIS"}
[_First billion-parameter diffusion model for weather \+ climate_]{style="color:var(--callout-color-caution)!important;"}
- Operates at the pixel level (1 × 1 patch size), guided by physical priors
- Medium-range forecast skill:
- **Surpasses IFS ENS, competitive with GenCast[^gen-cast]**
- Uniquely stable on seasonal scales to 90 days
:::
::: {.callout-note icon=false title="🌀 SWiPe"}
[_A novel 3D (sequence-window-pipeline) parallelism strategy for training transformers across high-resolution inputs_]{style="color:var(--callout-color-note)!important;"}
- Enables scalable small-batch training on large supercomputers[^aurora-scale]
- **10.21 ExaFLOPS**
- @ 121,000 Intel XPUs (Aurora)
:::
:::
[^gen-cast]: [GenCast: A Generative Model for Medium-Range Global Weather Forecasting](https://arxiv.org/html/2312.15796v1) (@price2024gencast)
[^aurora-scale]: Demonstrated on up to 120,960 GPUs on Aurora and 8,064 GPUs on LUMI.
### ⚠️ Issues with the Deterministic Approach
::: {.flex-container}
::: {.flex-child}
- [{{< iconify material-symbols close>}}]{.red-text} [**Transformers**]{.highlight-red}:
- *Deterministic*
- Single input → single forecast
:::
::: {.flex-child}
<!-- {{< iconify ph github-logo-duotone >}} -->
- [{{<iconify material-symbols check>}}]{.green-text} [**Diffusion**]{.highlight-green}:
- *Probabilistic*
- Single input → _**ensemble of forecasts**_
- Captures uncertainty and variability in weather predictions
- Enables ensemble forecasting for better risk assessment
:::
:::
### 🎲 Transitioning to a Probabilistic Model
::: {#fig-forward-pass}

Reverse diffusion with the [input]{style="color:#228be6"} condition, individual
sampling steps $t_{0} \rightarrow t_{64}$, the next time step
[estimate]{style="color:#40c057"} and the [target]{style="color:#fa5252"}
output.
:::
::: {.flex-container}
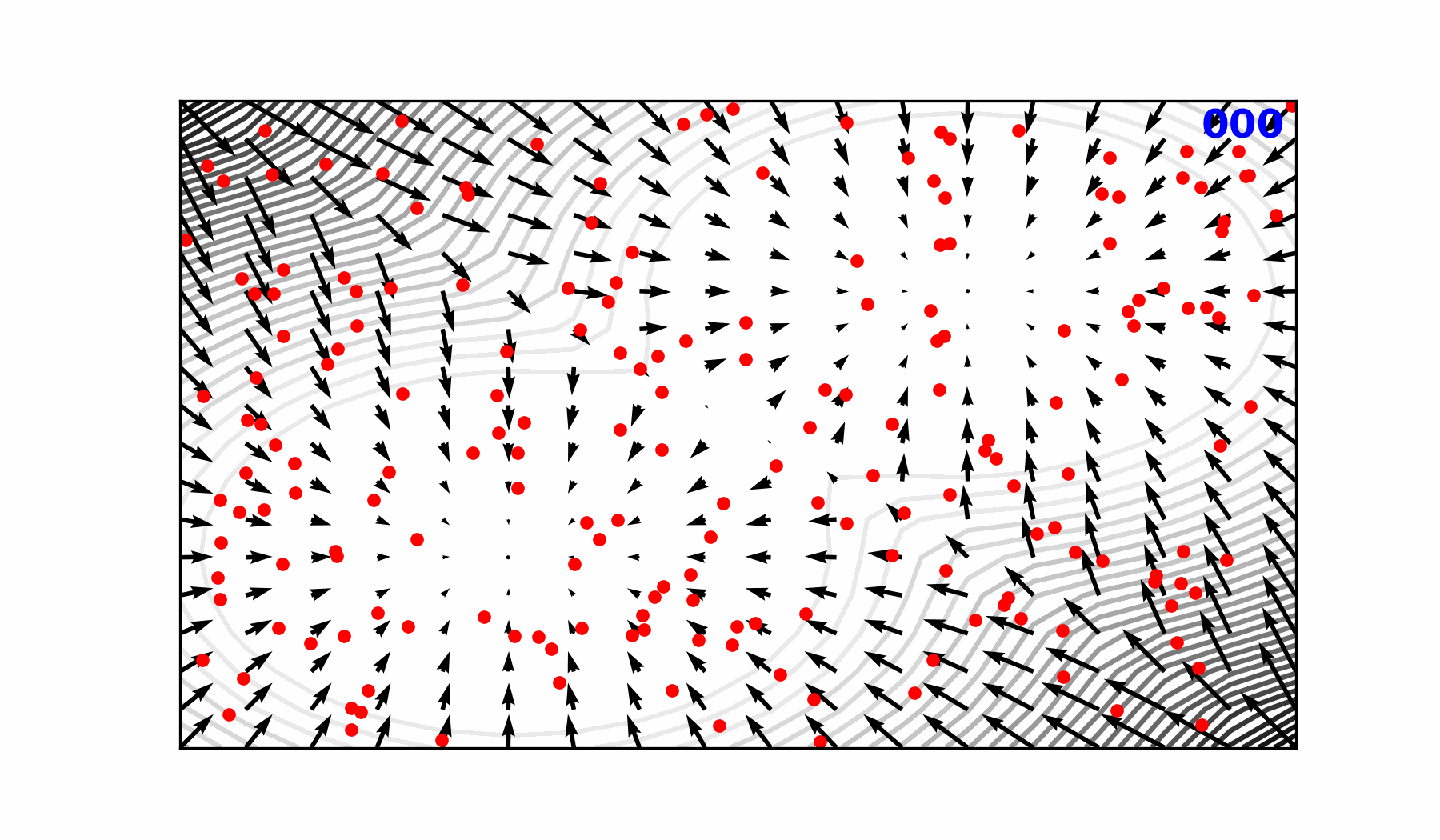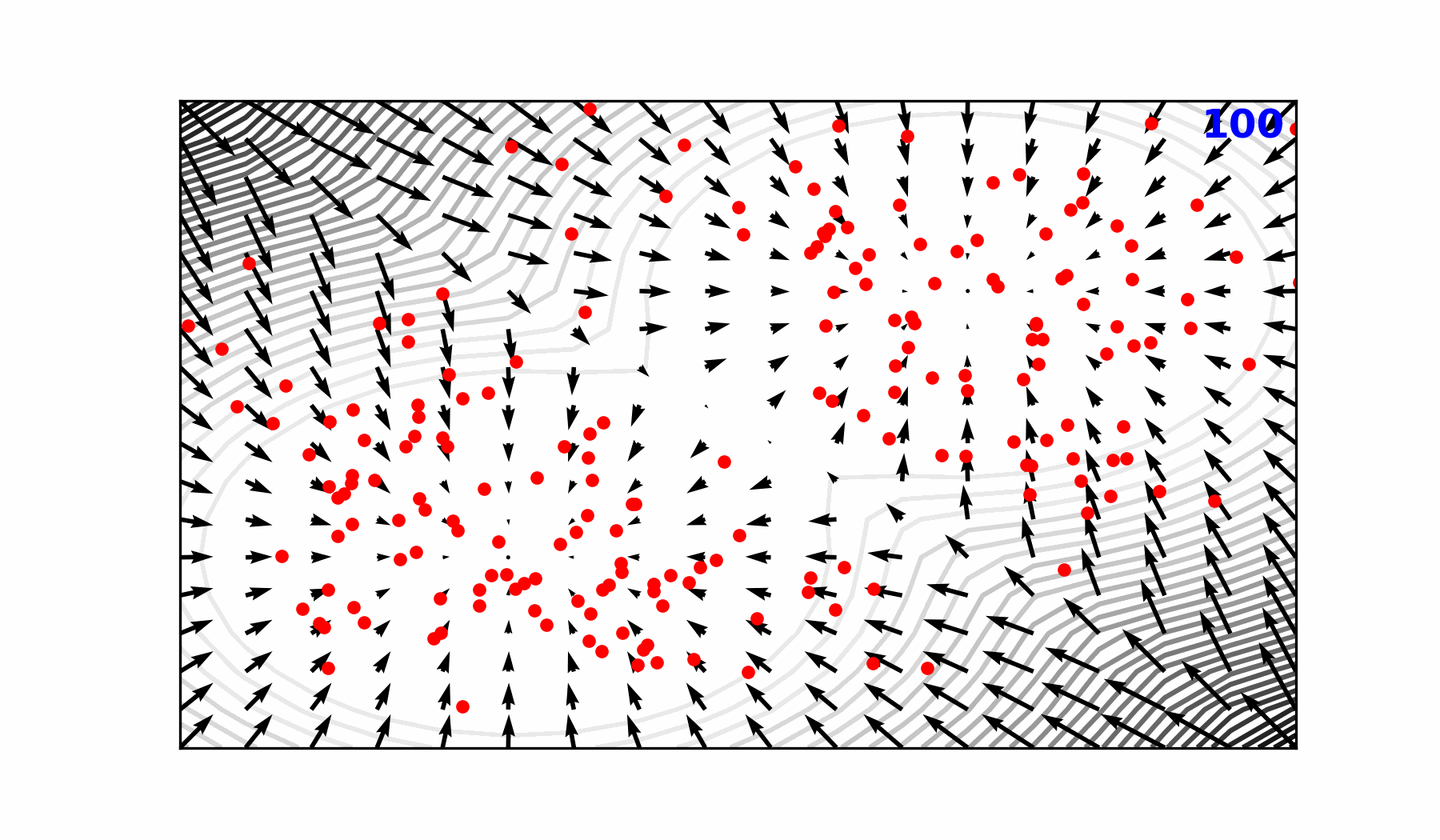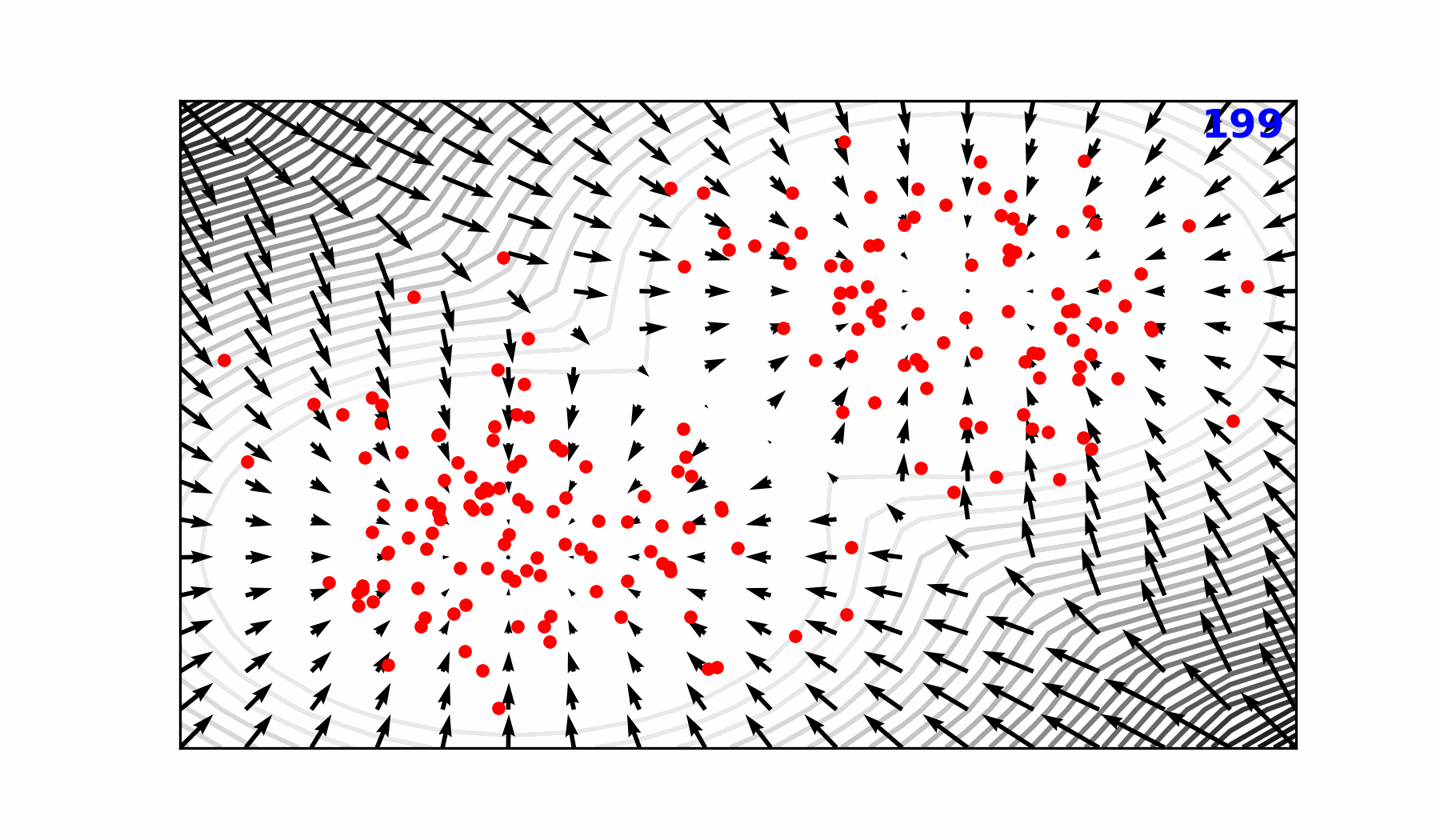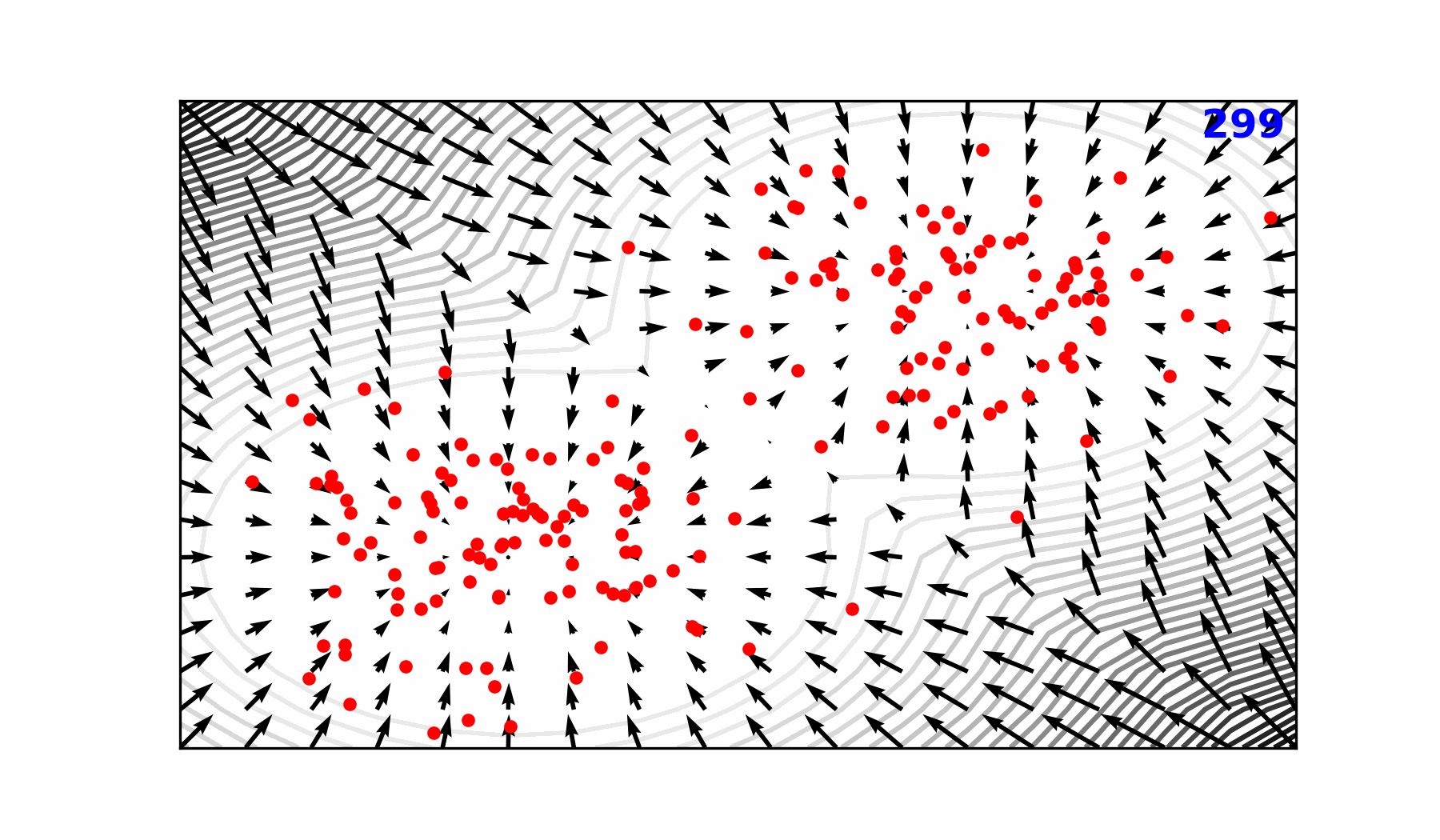
{width="89.6%"}
:::
### 🌀 Sequence-Window-Pipeline Parallelism `SWiPe` {.smaller}
::: {.content-visible unless-format="revealjs"}
::: {.flex-container}
::: {.column style="width:33%;"}
- `SWiPe` is a **novel parallelism strategy** for Swin-based Transformers
- Hybrid 3D Parallelism strategy, combining:
- Sequence parallelism (`SP`)
- Window parallelism (`WP`)
- Pipeline parallelism (`PP`)
:::
::: {#fig-swipe-layer style="width:66%;"}

:::
:::
::: {#fig-comms style="width:80%; text-align: center; margin-left: auto; margin-right: auto; "}

`SWiPe` Communication Patterns
:::
:::
::: {.content-visible when-format="revealjs"}
::: {.flex-container}
::: {.column style="width:33%;"}
- `SWiPe` is a **novel parallelism strategy** for Swin-based Transformers
- Hybrid 3D Parallelism strategy, combining:
- Sequence parallelism (`SP`)
- Window parallelism (`WP`)
- Pipeline parallelism (`PP`)
:::
::: {#fig-swipe-layer style="width:66%;"}

:::
:::
::: {#fig-comms style="width:60%; text-align: center; margin-left: auto; margin-right: auto;"}

`SWiPe` Communication Patterns
:::
:::
### 🚀 AERIS: Scaling Results
::: {.flex-container}
::: {.column #fig-aeris-scaling style="width:70%;"}

AERIS: Scaling Results
:::
::: {.column style="width:30%;"}
- [**10 EFLOPs**]{.highlight-blue} (sustained) @ **120,960 GPUs**
- See (@stock2025aeris) for additional details
- [arXiv:2509.13523](https://arxiv.org/abs/2509.13523)
:::
:::
### 🌪️ Hurricane Laura
::: {#fig-hurricane-laura}
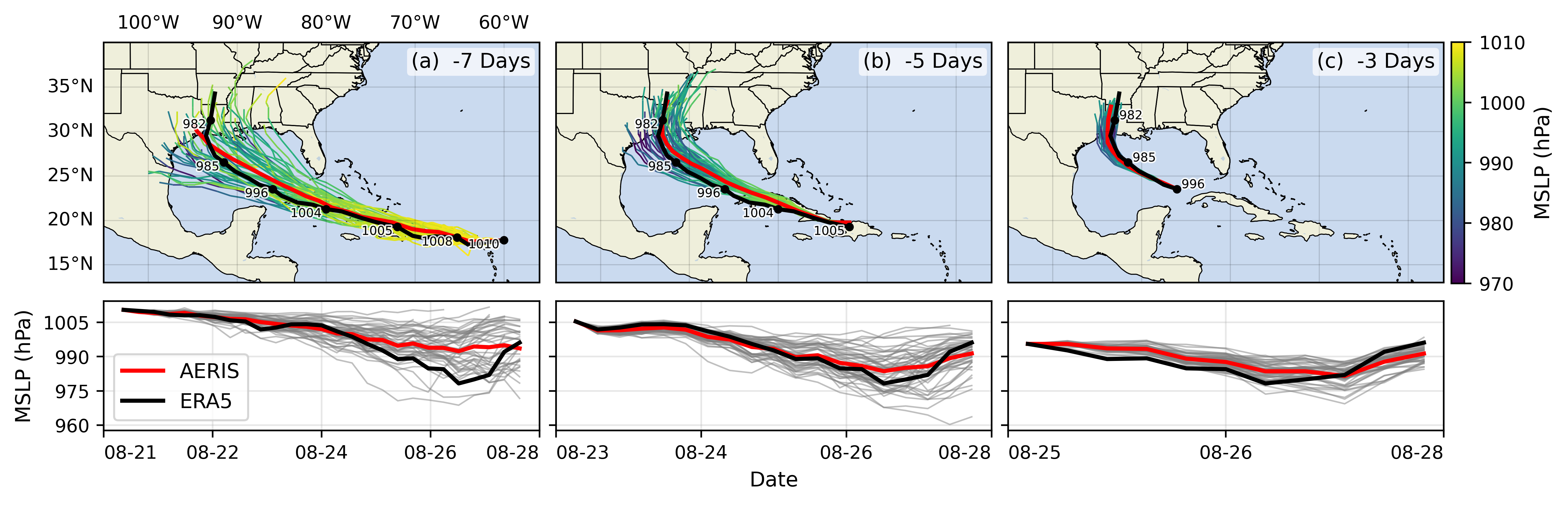
Hurricane Laura tracks (top) and intensity (bottom). Initialized 7(a), 5(b) and
3(c) days prior to 2020-08-28T00z.
:::
## 📓 References
::: {#refs}
:::
## ❤️ Acknowledgements
> This research used resources of the Argonne Leadership Computing
> Facility, which is a DOE Office of Science User Facility supported
> under Contract DE-AC02-06CH11357.
## Extras




































