AuroraGPT: Training Foundation Models on Supercomputers

@ Argonne National Laboratory
2025-12-16
👥 Team Leads
Planning






Data

Training


Evaluation



Post


Inference

Comms


Distribution

🍹 AuroraGPT: Blending Data, Efficiently
- 🐢 Original implementation:
- Slow (serial, single device)
- ~ 1 hr/2T tokens
- 🐇 New implementation:
- Fast! (distributed, asynchronous)
- ~ 2 min/2T tokens
(30x faster !!)

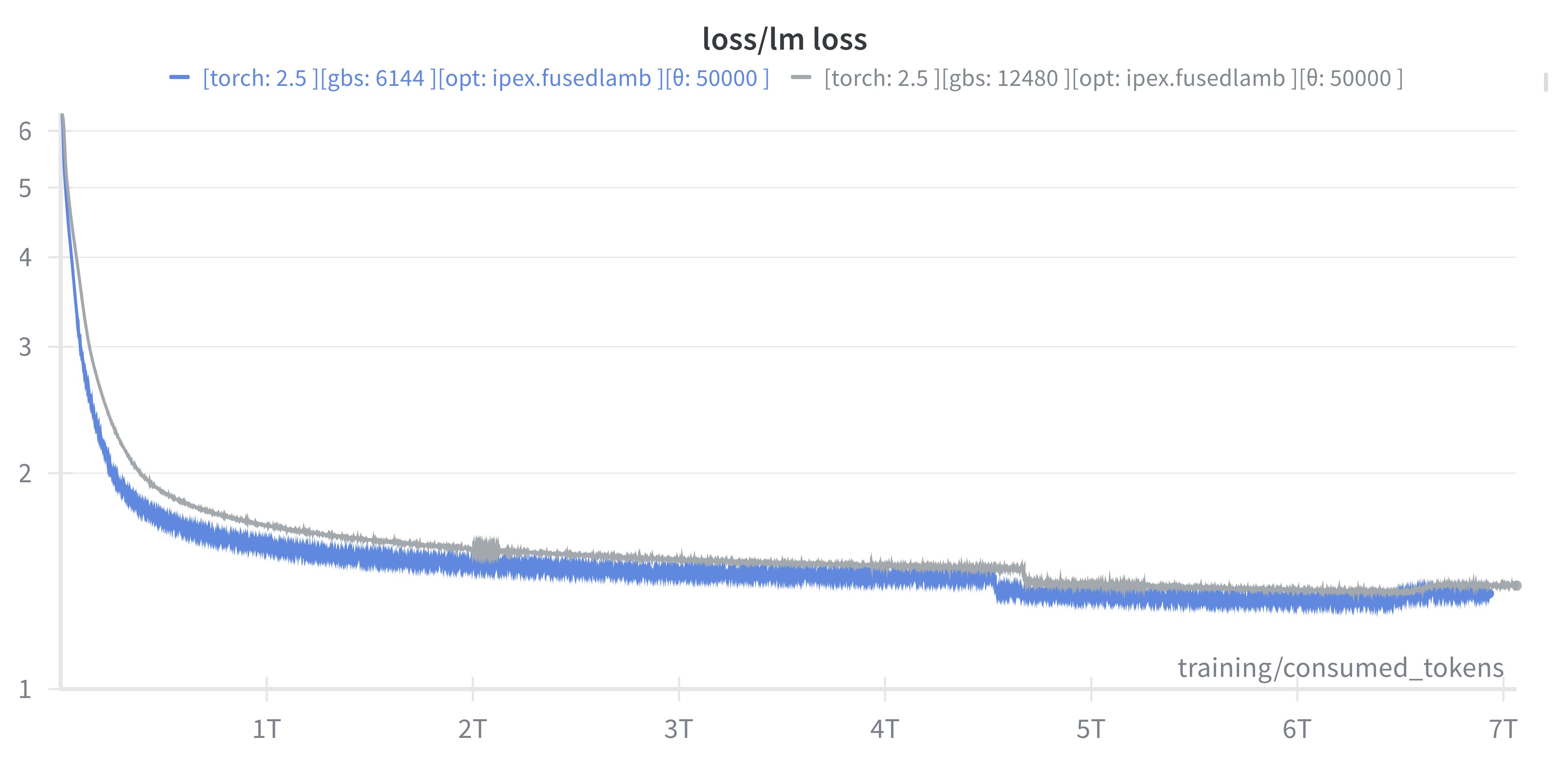
📉 Training AuroraGPT-7B on 2T Tokens

📉 Training AuroraGPT-2B on 7T Tokens
🧬 Scaling Results (2024)

3.5B model across ~38,400 GPUs
~ 4 EFLOPS @ Aurora
38,400 XPUs
= 3200 [node] x 12 [XPU / node]-
- MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows (Dharuman et al. (2024))
🧬 MProt-DPO: Scaling Results
3.5B model

7B model
🚂 Loooooooooong Sequence Lengths

![]()
- Working with Microsoft/DeepSpeed team to enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details


SEQ_LEN for both 25B and 33B models (See: Song et al. (2023))
🌎 AERIS (2025)


👀 High-Level Overview of AERIS
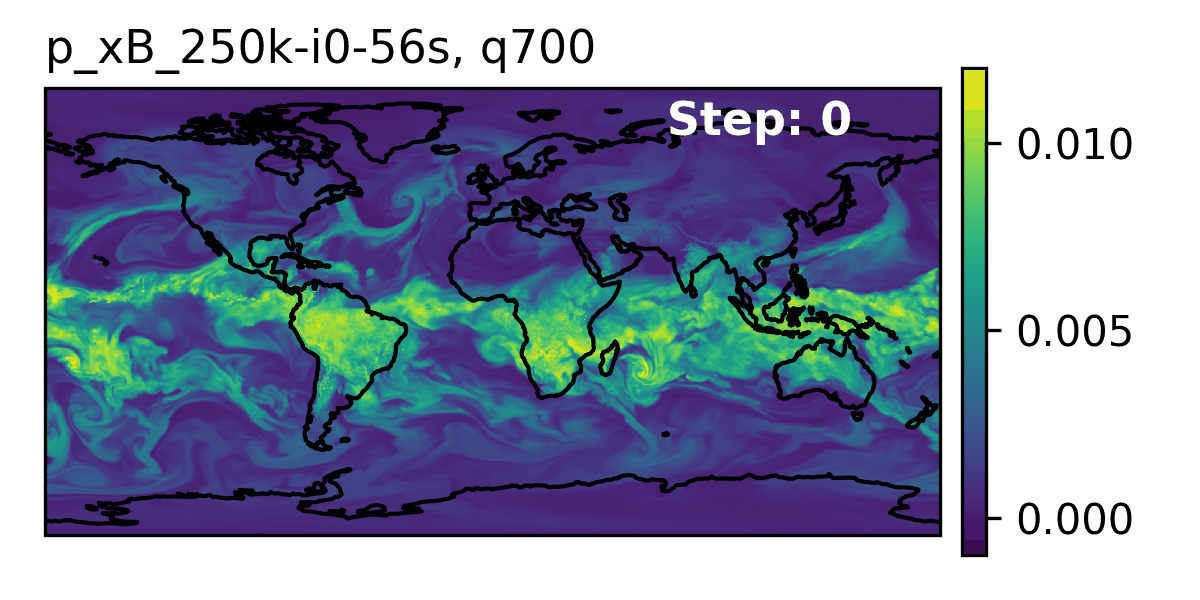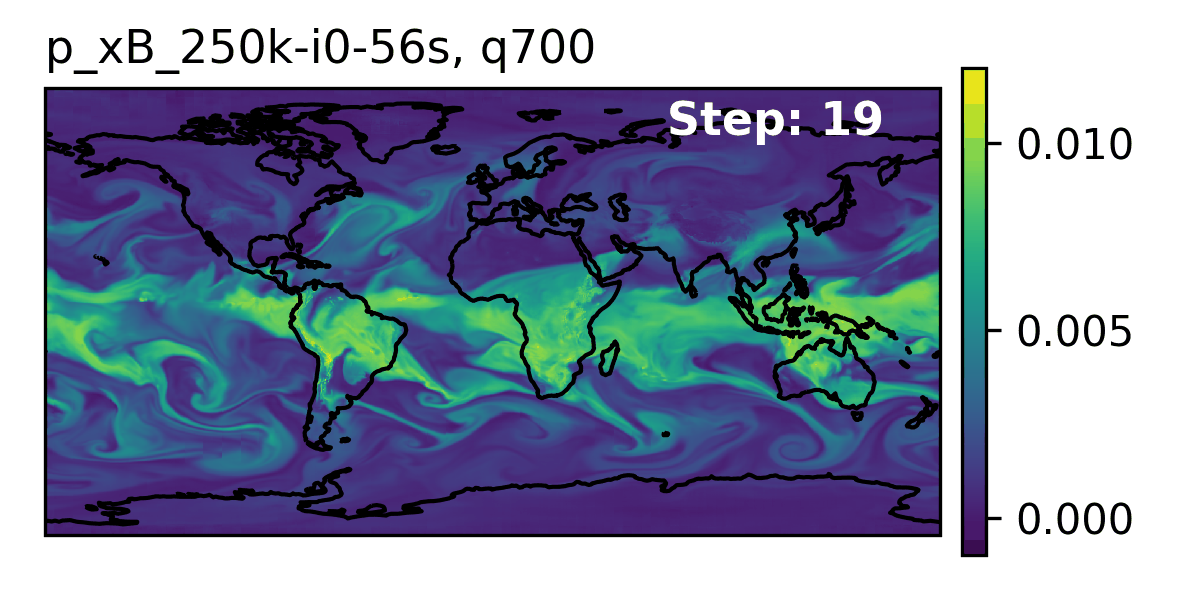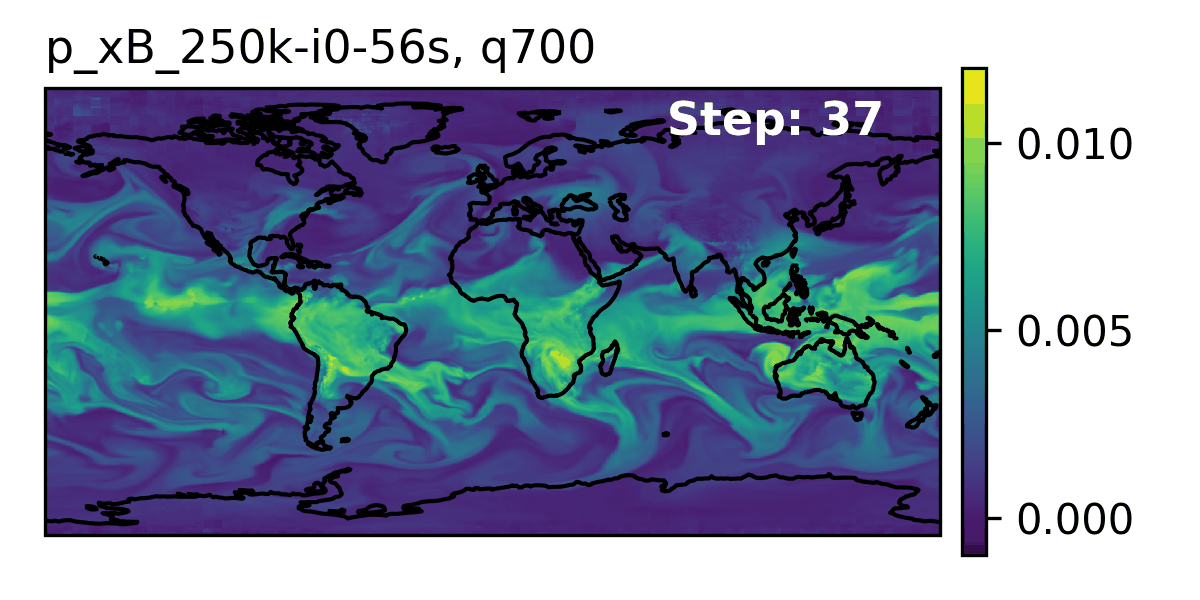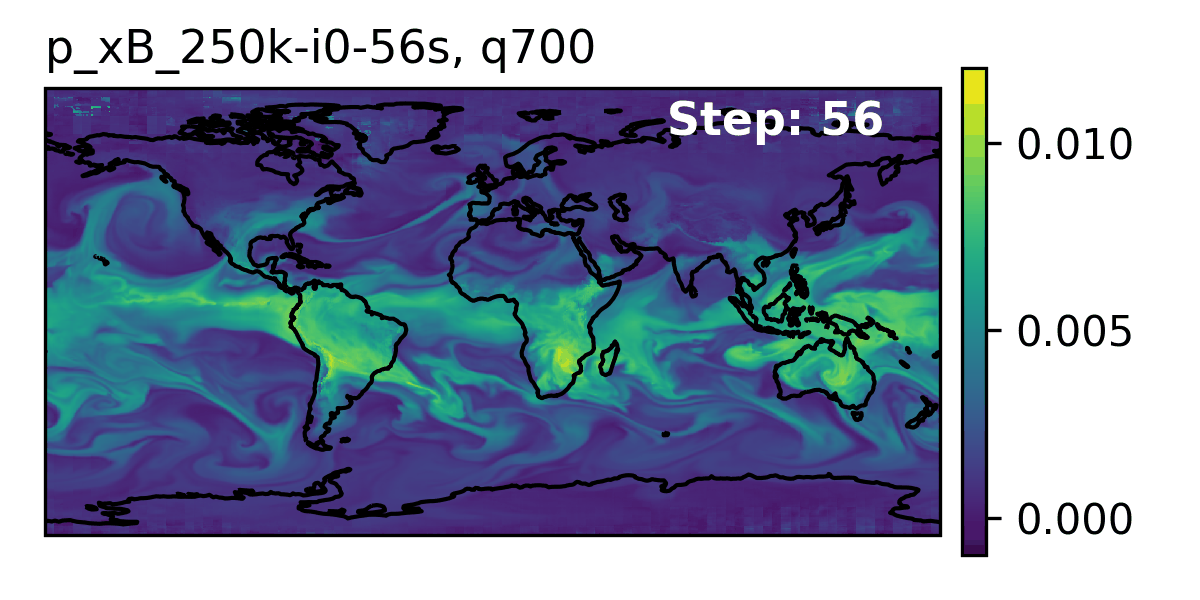
| Property | Description |
|---|---|
| Domain | Global |
| Resolution | 0.25° & 1.4° |
| Training Data | ERA5 (1979–2018) |
| Model Architecture | Swin Transformer |
| Speedup1 | O(10k–100k) |
🎲 Transitioning to a Probabilistic Model

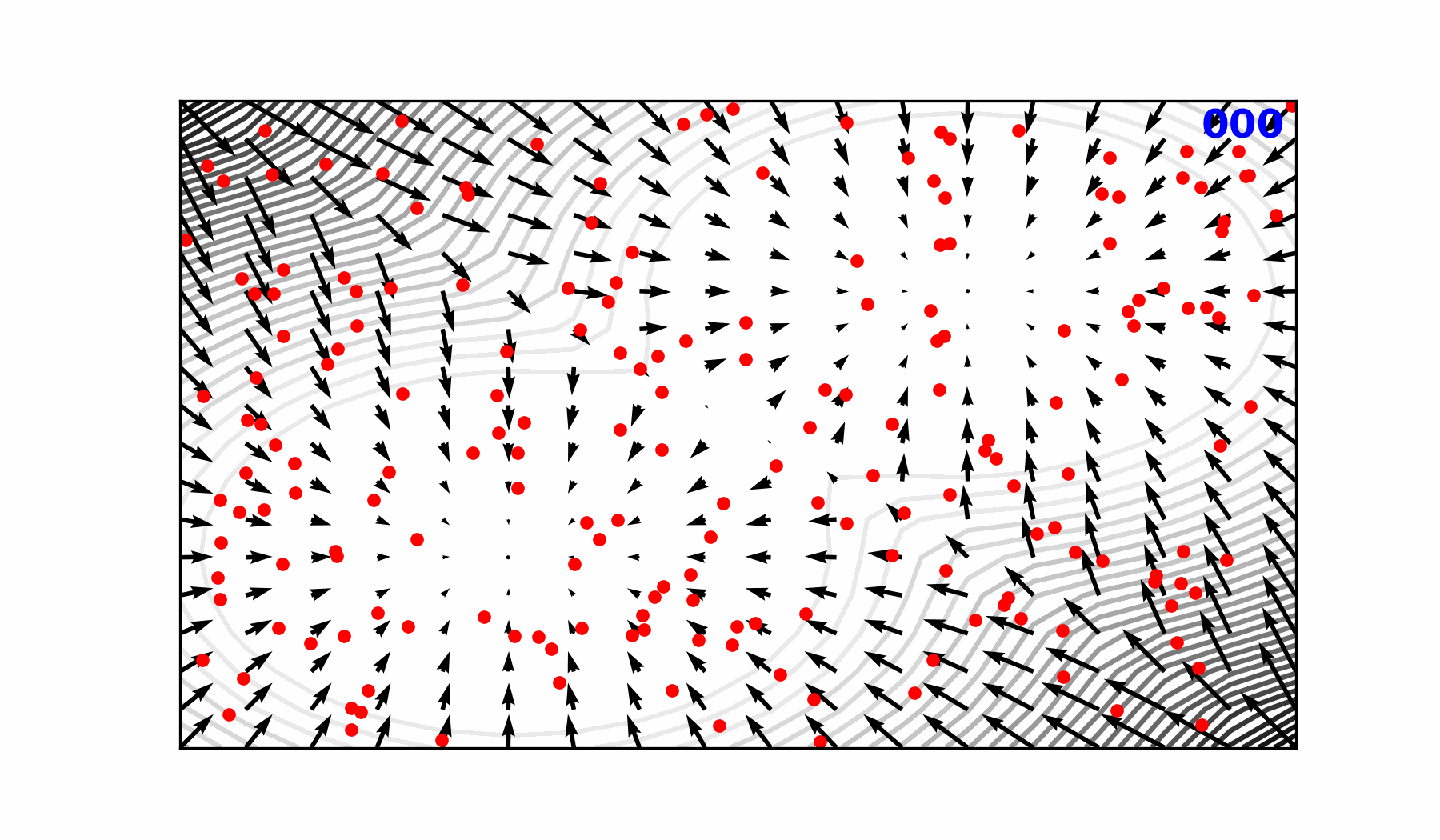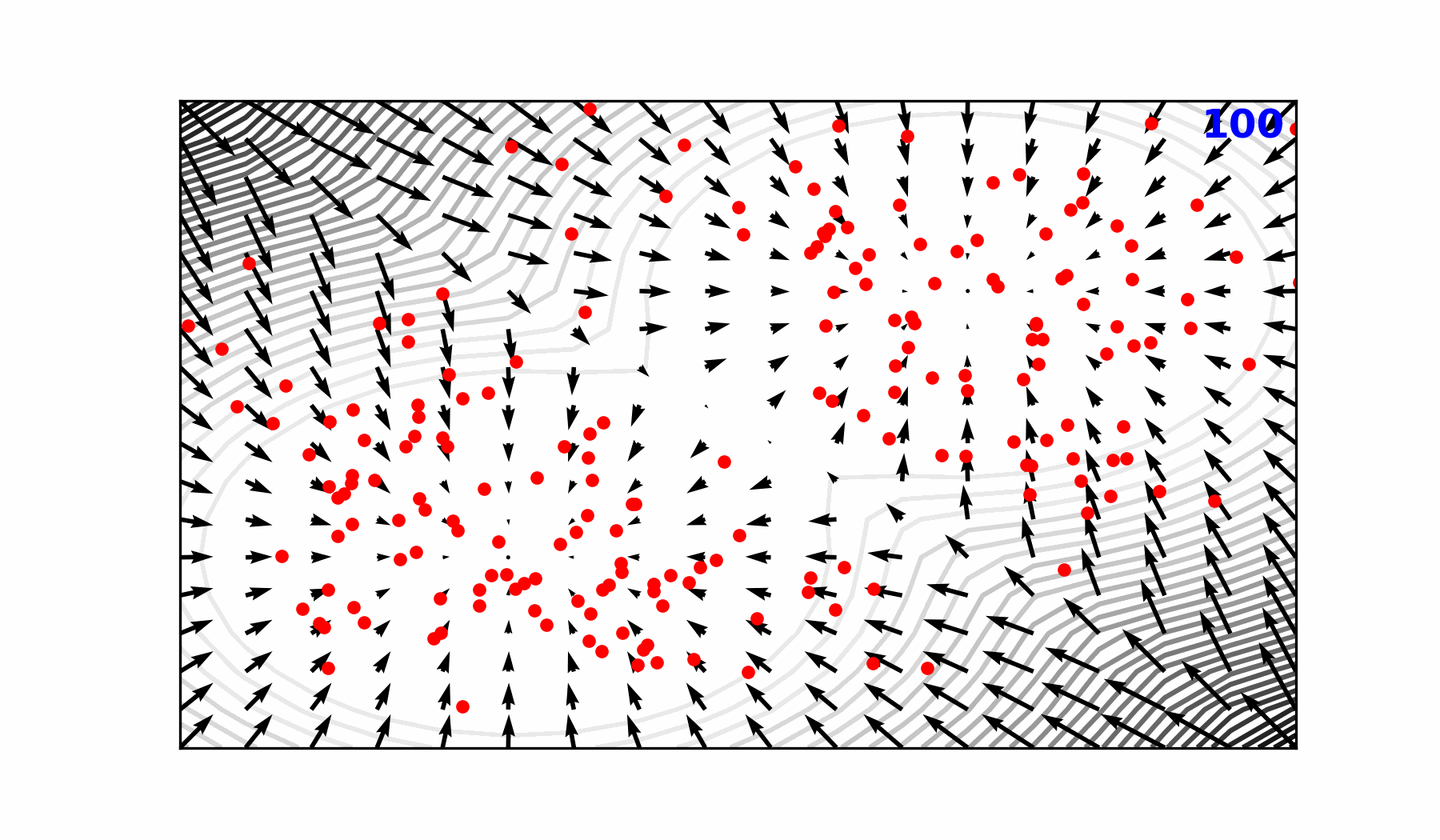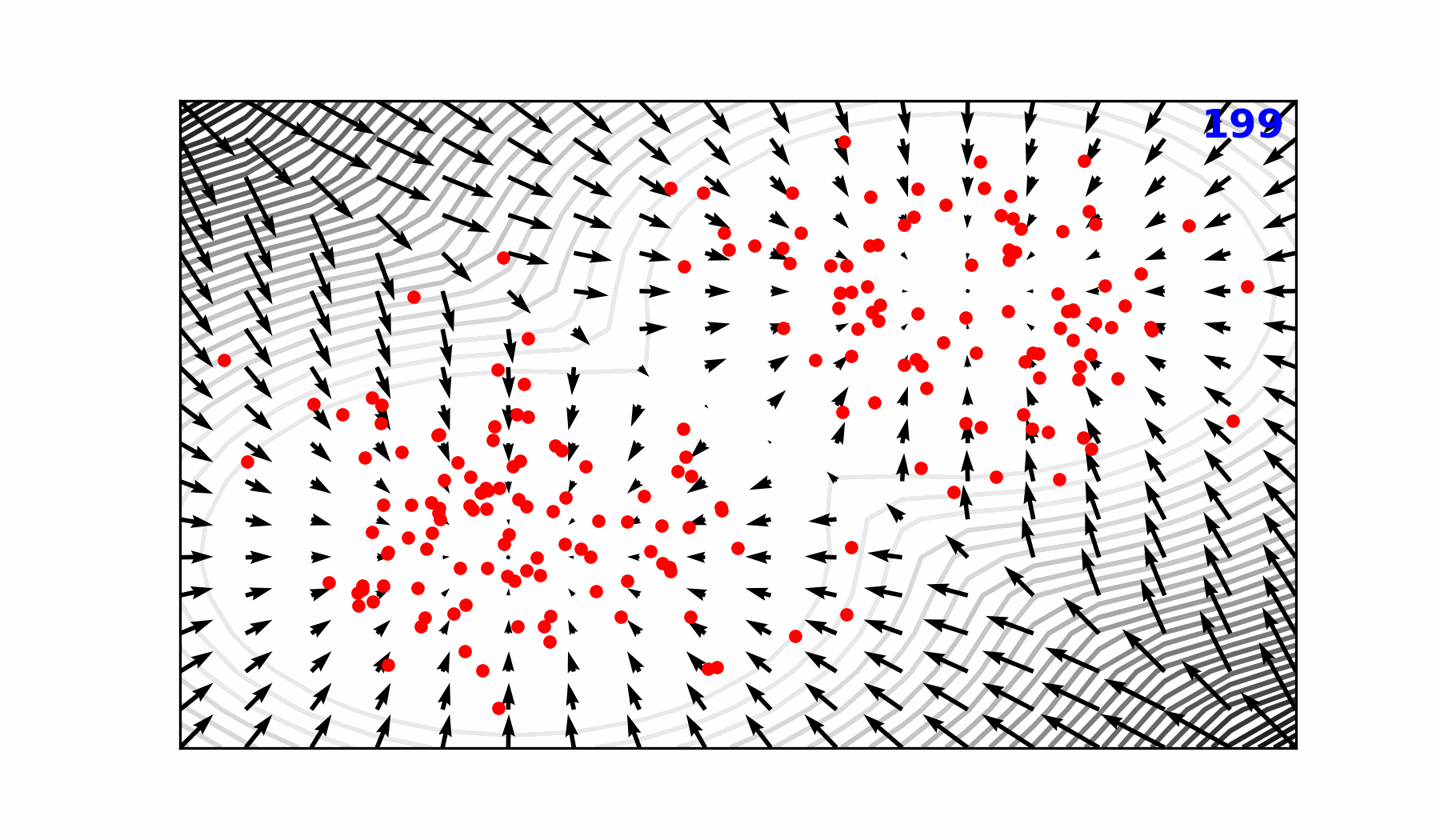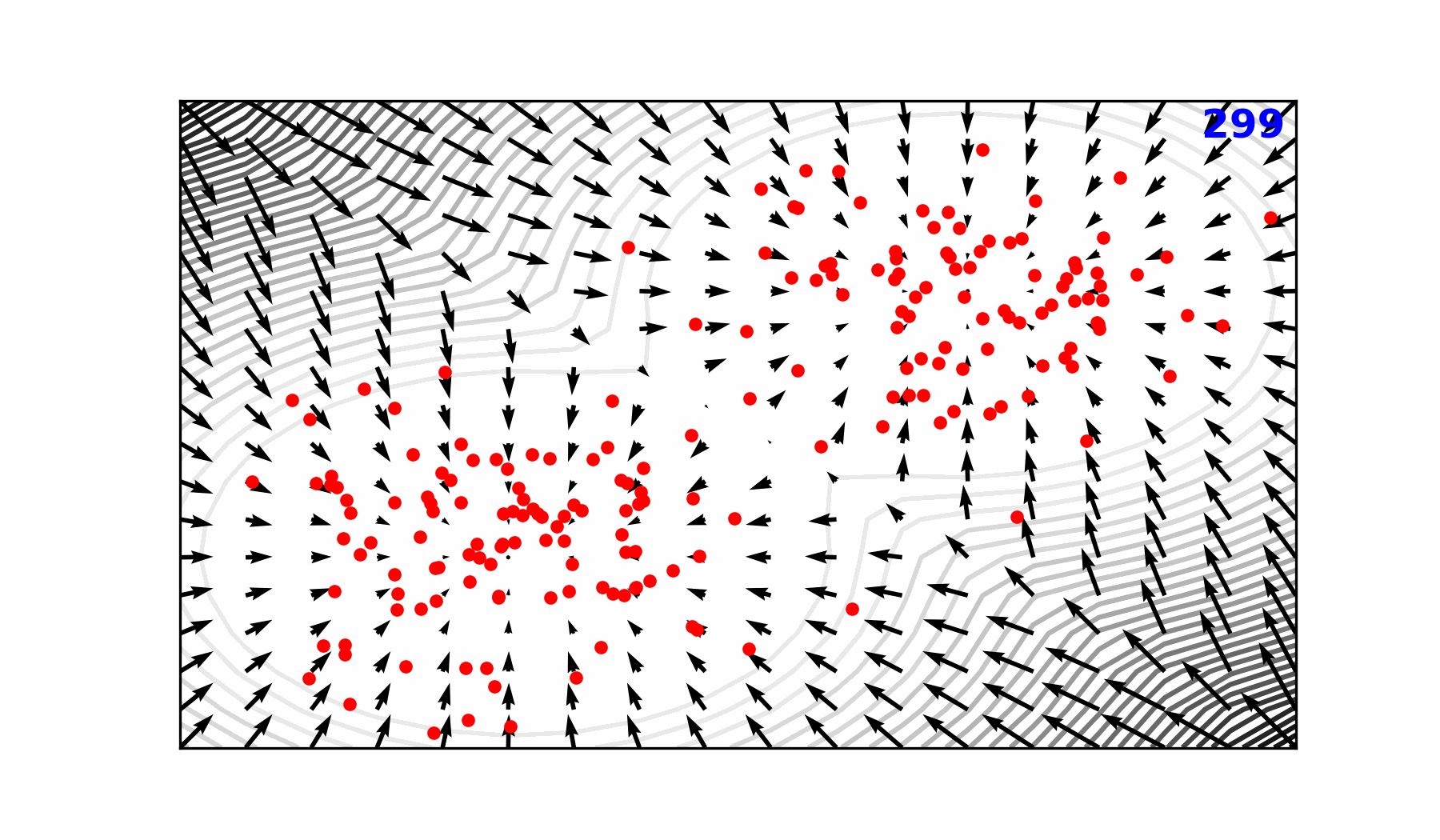
🌀 Sequence-Window-Pipeline Parallelism SWiPe
SWiPeis a novel parallelism strategy for Swin-based Transformers- Hybrid 3D Parallelism strategy, combining:
- Sequence parallelism (
SP) - Window parallelism (
WP) - Pipeline parallelism (
PP)
- Sequence parallelism (


SWiPe Communication Patterns
🚀 AERIS: Scaling Results

- 10 EFLOPs (sustained) @ 120,960 GPUs
- See (Hatanpää et al. (2025)) for additional details
- arXiv:2509.13523
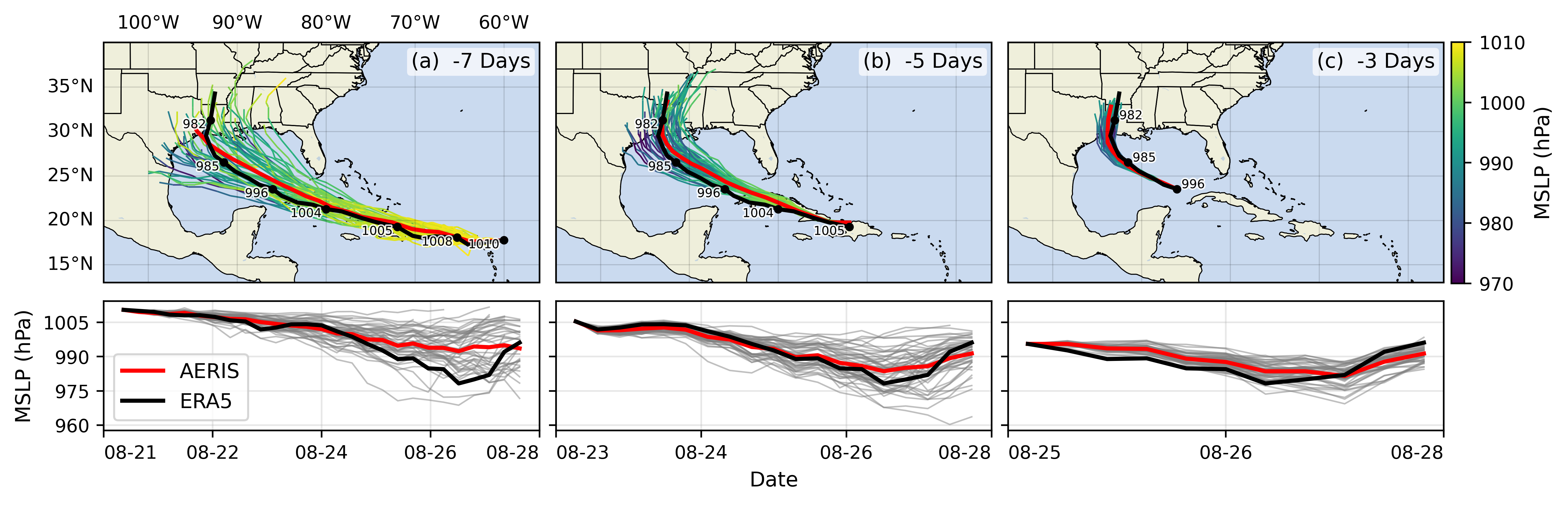
🌪️ Hurricane Laura