Training Foundation Models on Supercomputers

@ University of Illinois at Urbana-Champaign
2025-10-24
Argonne Leadership Computing Facility (ALCF)
The ALCF enables breakthroughs in science and engineering by providing supercomputing resources and expertise to the research community.
–alcf.anl.gov


🏗️ Aurora
| Property | Value |
|---|---|
| Racks | 166 |
| Nodes | 10,624 |
| XPUs2 | 127,488 |
| CPUs | 21,248 |
| NICs | 84,992 |
| HBM | 8 PB |
| DDR5c | 10 PB |

🤖 ALCF AI Testbed
- ALCF AI Testbed Systems are in production and available for allocations to the research community
- Significant improvement in time-to-solution and energy-efficiency for diverse AI for science applications.
- NAIRR Pilot
Up to 25\times improvement for genomic foundation models with 6.5\times energy efficiency




🔭 AI-for-Science
ChatGPT: explain this image
🌌 AuroraGPT (2024–)
AuroraGPT: General purpose scientific LLM Broadly trained on a general corpora plus scientific {papers, texts, data}
- Explore pathways towards a “Scientific Assistant” model
- Build with international partners (RIKEN, BSC, others)
- Multimodal: images, tables, equations, proofs, time series, graphs, fields, sequences, etc
Awesome-LLM
🧪 AuroraGPT: Open Science Foundation Model

👥 Team Leads
Planning






Data

Training


Evaluation



Post


Inference

Comms


Distribution

🍹 AuroraGPT: Blending Data, Efficiently
- 🐢 Original implementation:
- Slow (serial, single device)
- ~ 1 hr/2T tokens
- 🐇 New implementation:
- Fast! (distributed, asynchronous)
- ~ 2 min/2T tokens
(30x faster !!)

📉 Training AuroraGPT-7B on 2T Tokens

📉 Training AuroraGPT-2B on 7T Tokens
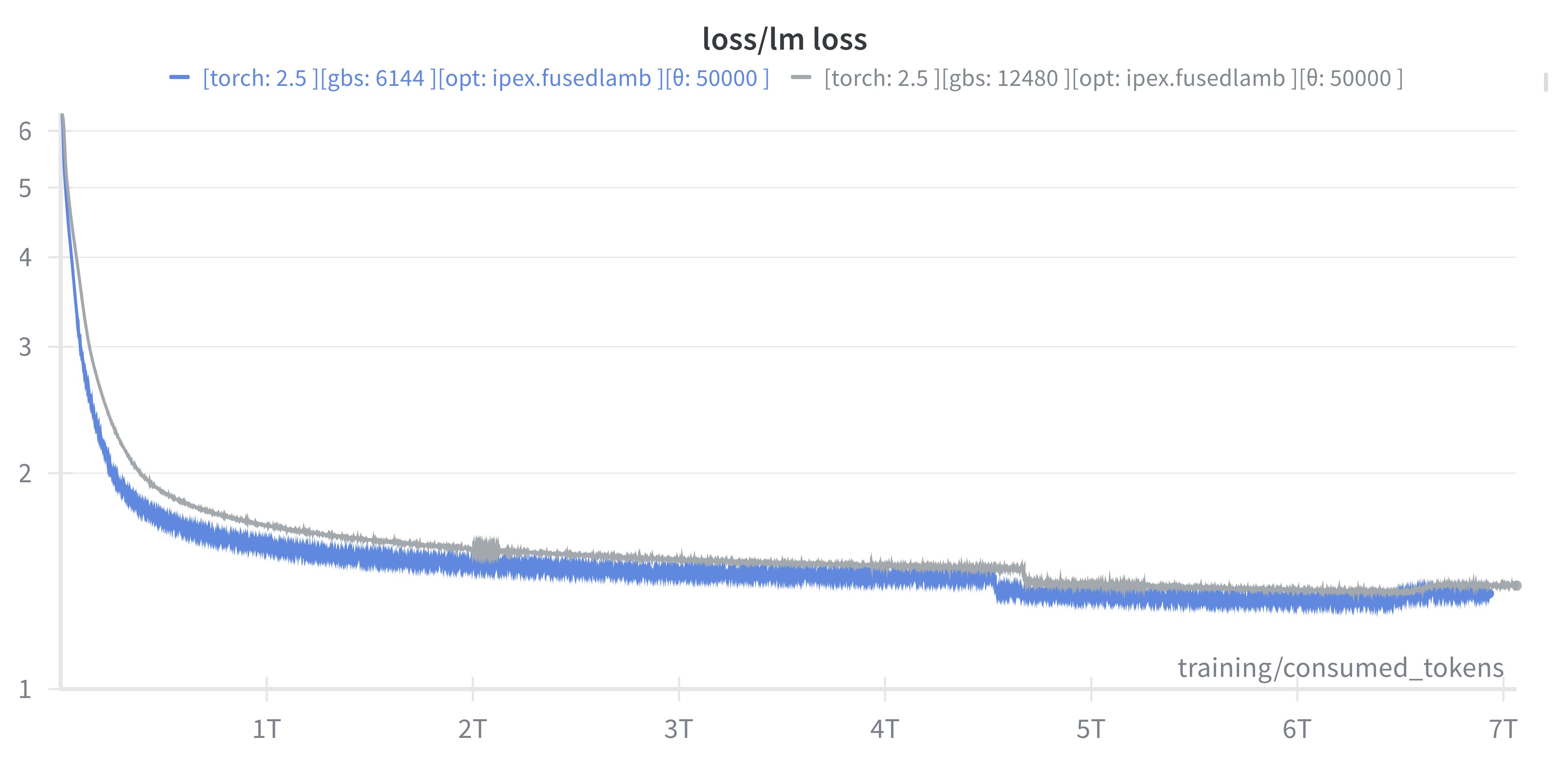
🧬 Scaling Results (2024)

3.5B model across ~38,400 GPUs
~ 4 EFLOPS @ Aurora
38,400 XPUs
= 3200 [node] x 12 [XPU / node]-
- MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows (Dharuman et al. (2024))
🧬 MProt-DPO: Scaling Results
3.5B model

7B model
🚂 Loooooooooong Sequence Lengths

![]()
- Working with Microsoft/DeepSpeed team to enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details


SEQ_LEN for both 25B and 33B models (See: Song et al. (2023))
🌎 AERIS (2025)


👀 High-Level Overview of AERIS
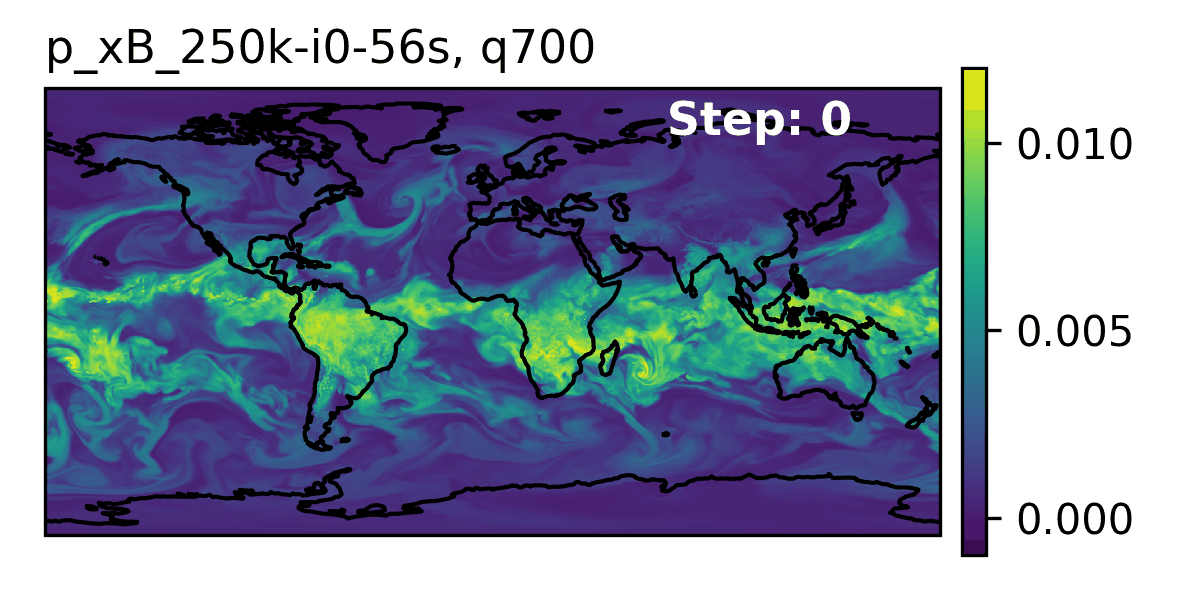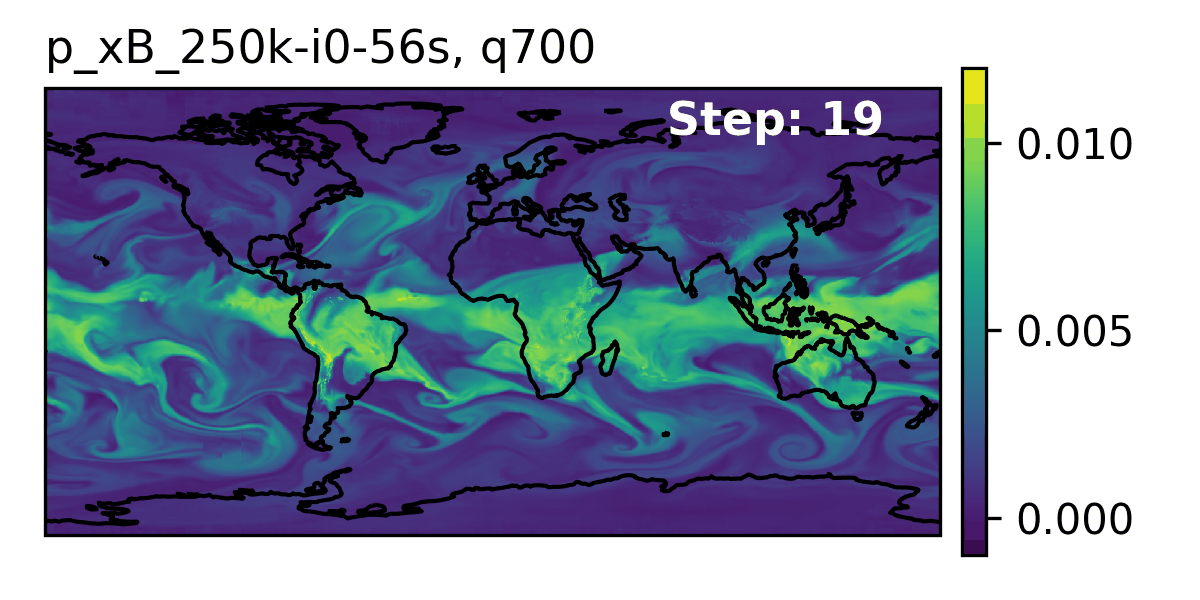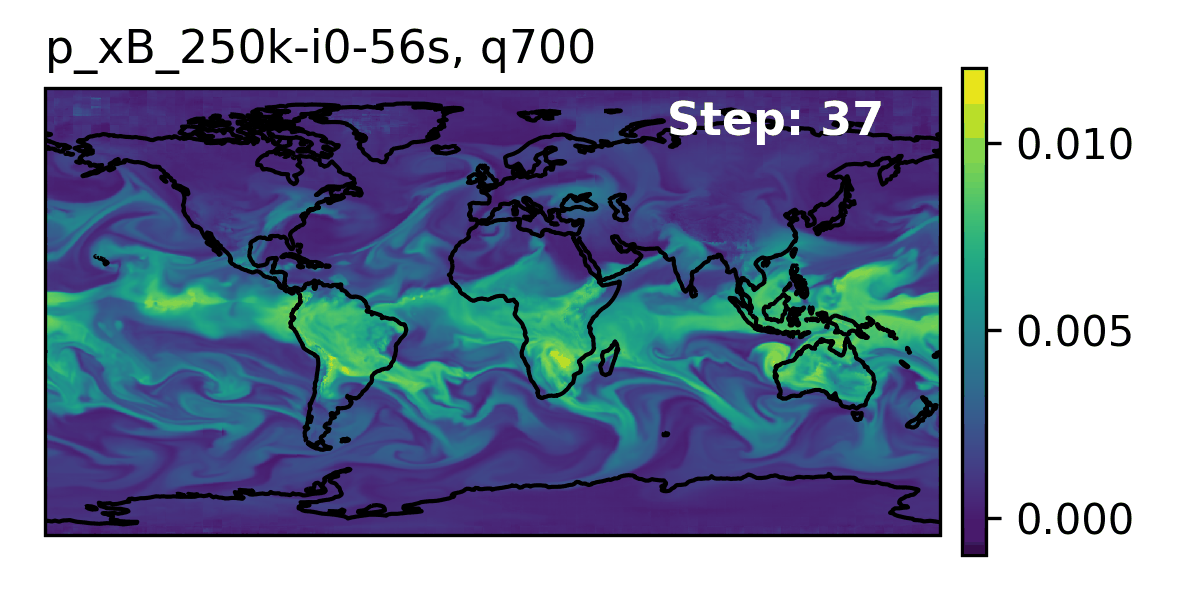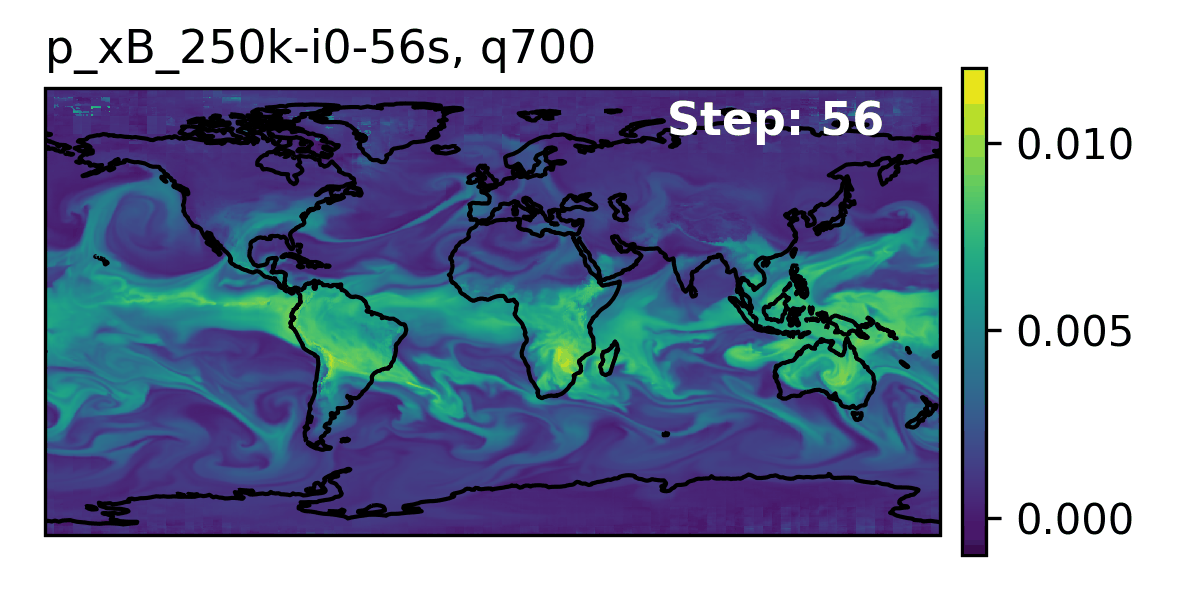
| Property | Description |
|---|---|
| Domain | Global |
| Resolution | 0.25° & 1.4° |
| Training Data | ERA5 (1979–2018) |
| Model Architecture | Swin Transformer |
| Speedup1 | O(10k–100k) |
🎲 Transitioning to a Probabilistic Model

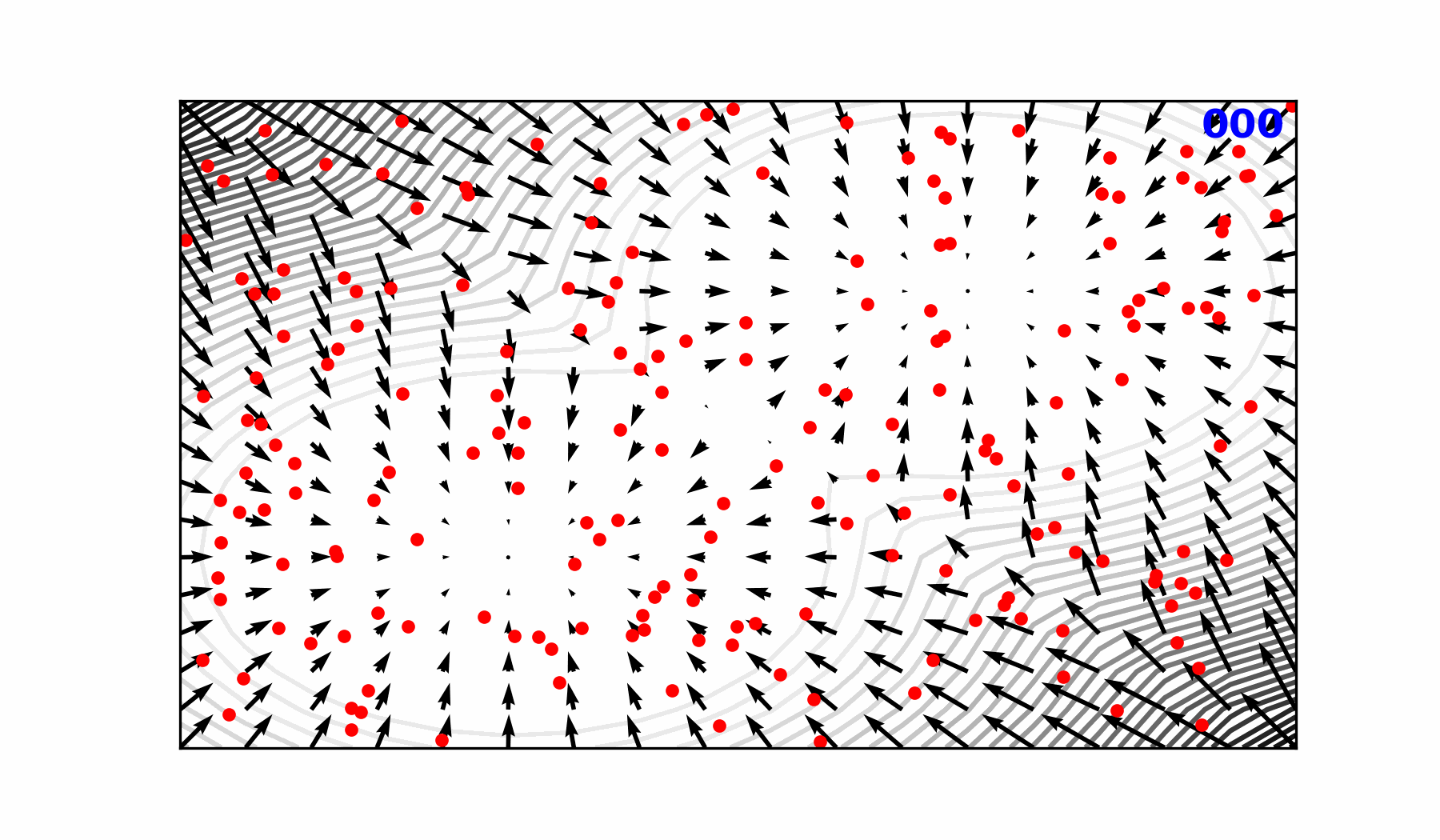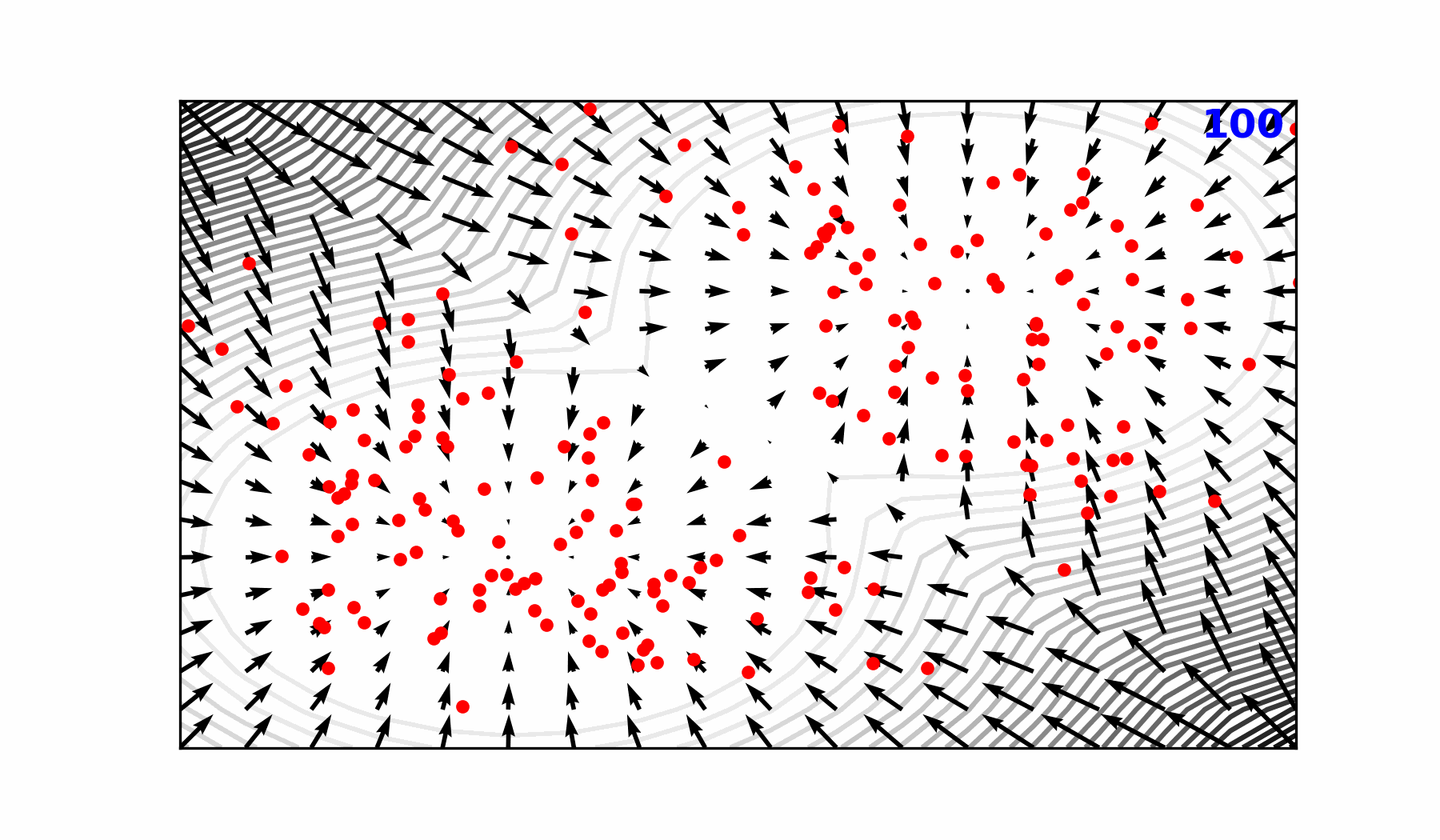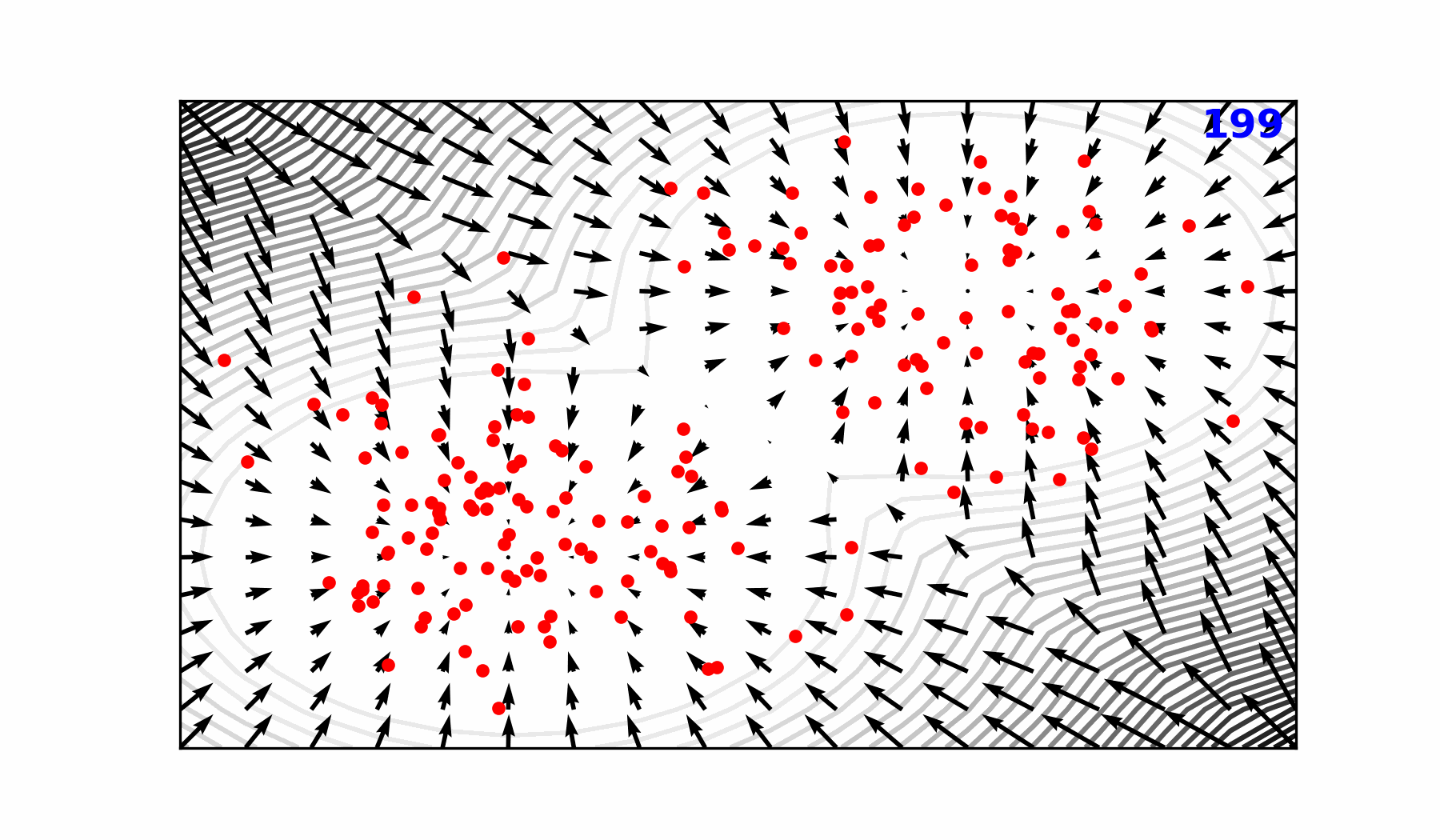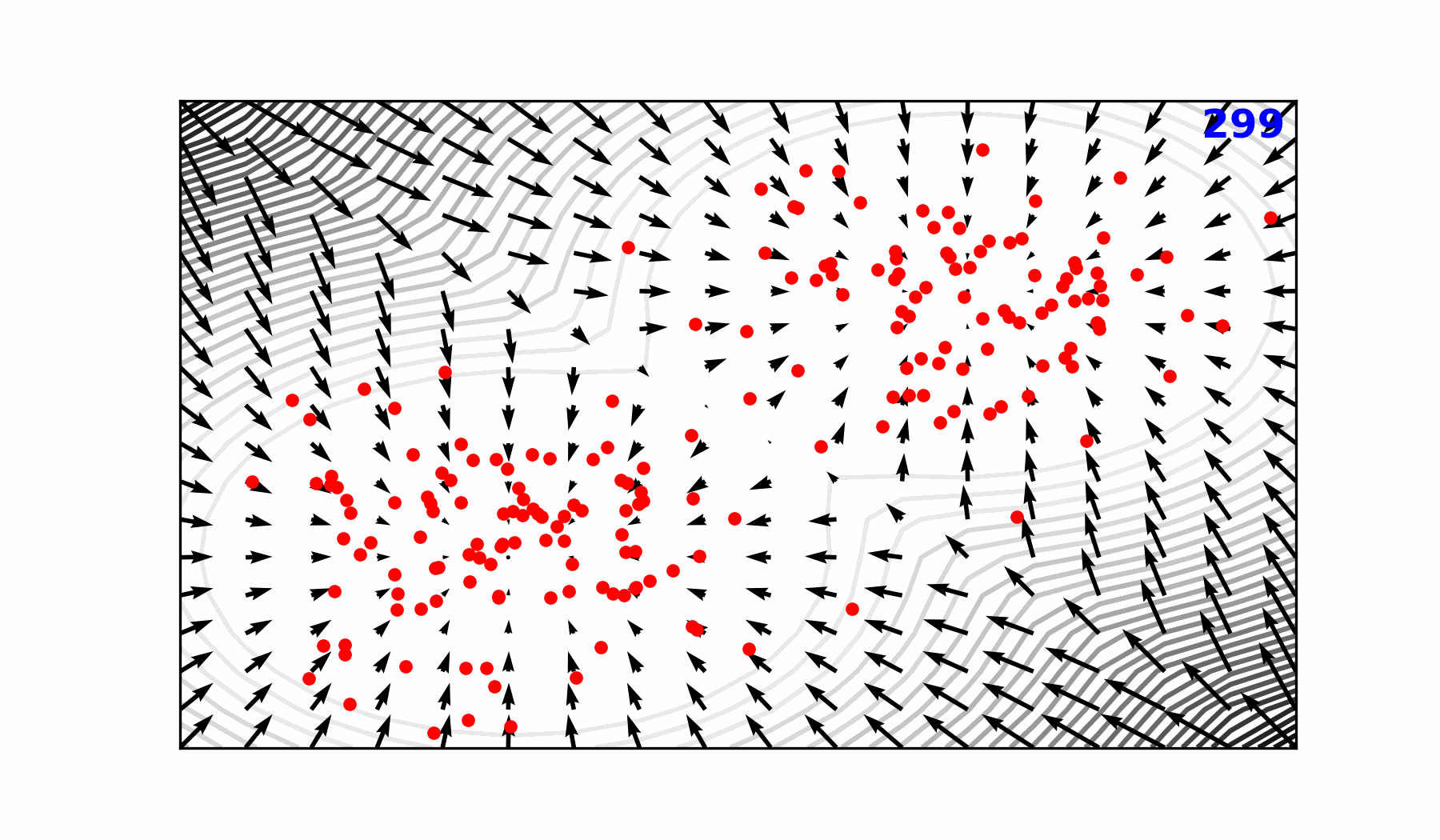
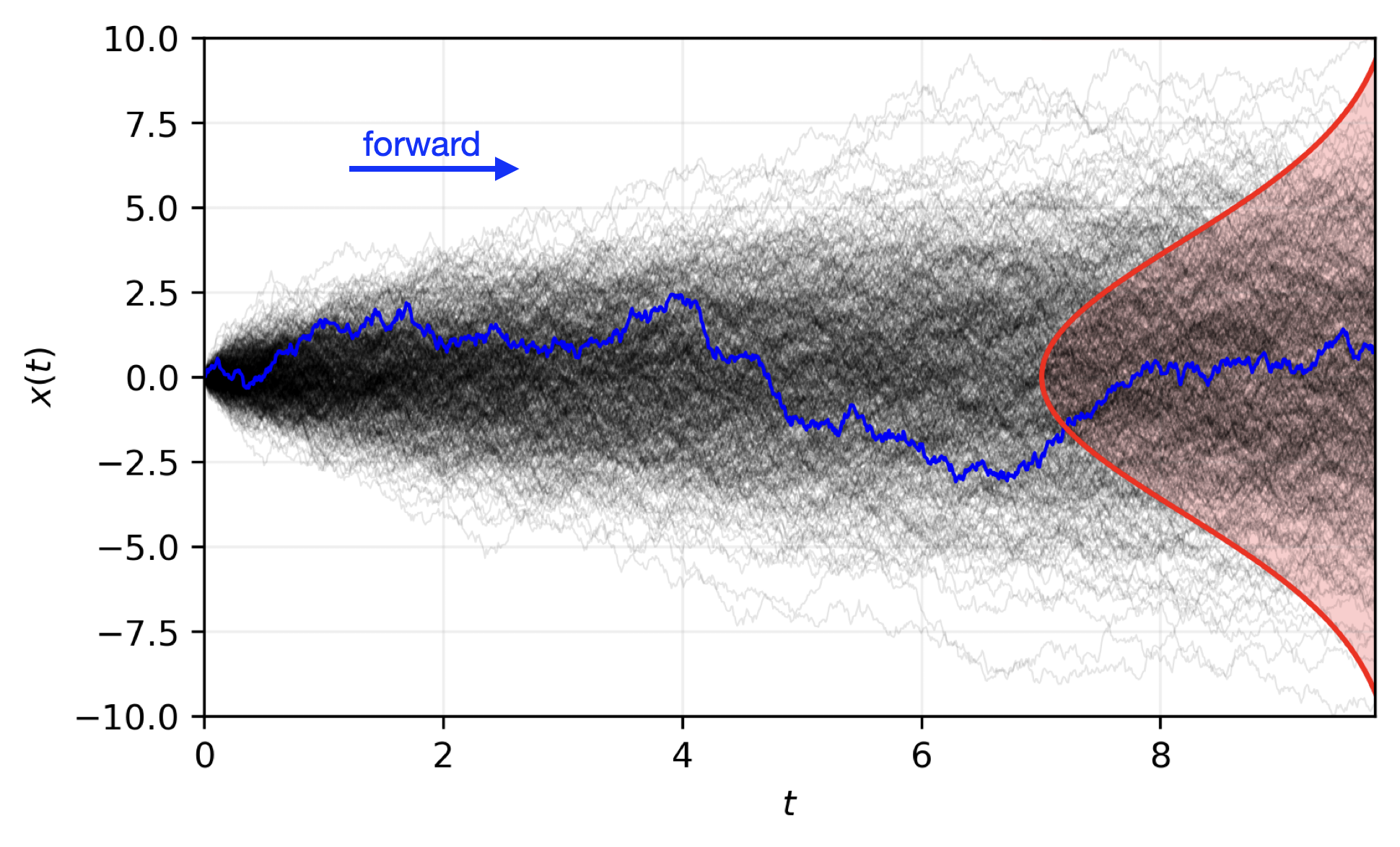
🌀 Sequence-Window-Pipeline Parallelism SWiPe
SWiPeis a novel parallelism strategy for Swin-based Transformers- Hybrid 3D Parallelism strategy, combining:
- Sequence parallelism (
SP) - Window parallelism (
WP) - Pipeline parallelism (
PP)
- Sequence parallelism (


SWiPe Communication Patterns
🚀 AERIS: Scaling Results

- 10 EFLOPs (sustained) @ 120,960 GPUs
- See (Hatanpää et al. (2025)) for additional details
- arXiv:2509.13523
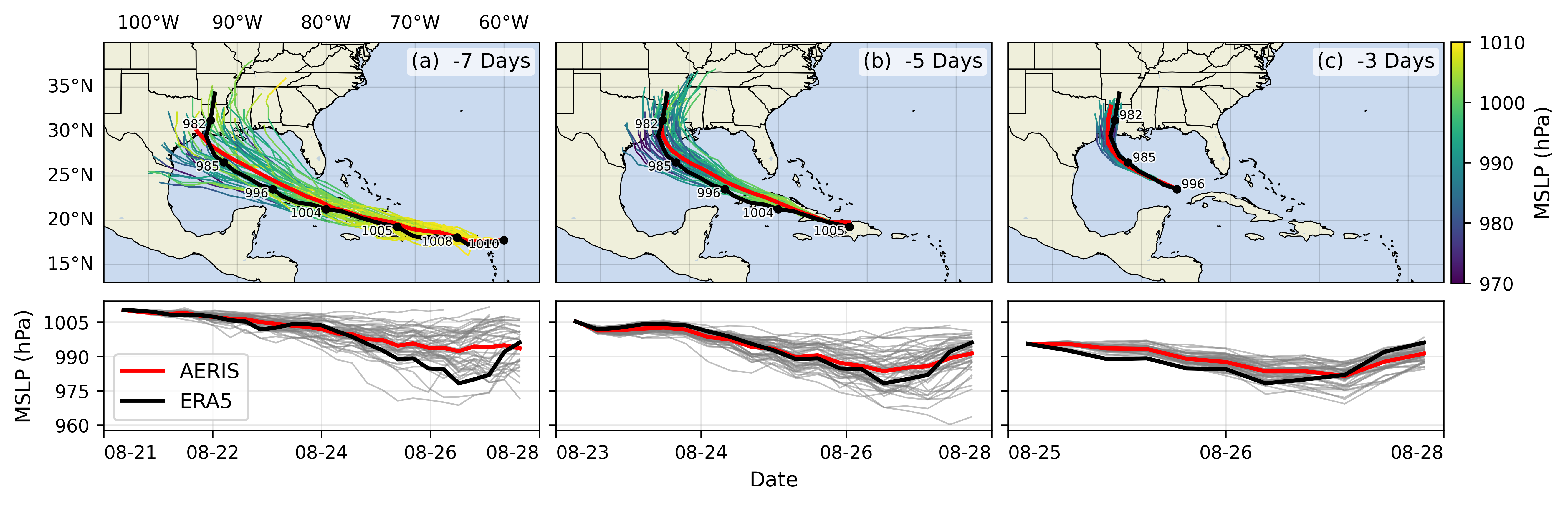
🌪️ Hurricane Laura