AuroraGPT
Large Scale Training on Diverse Accelerators
Argonne National Laboratory
🎯 AuroraGPT: Goals
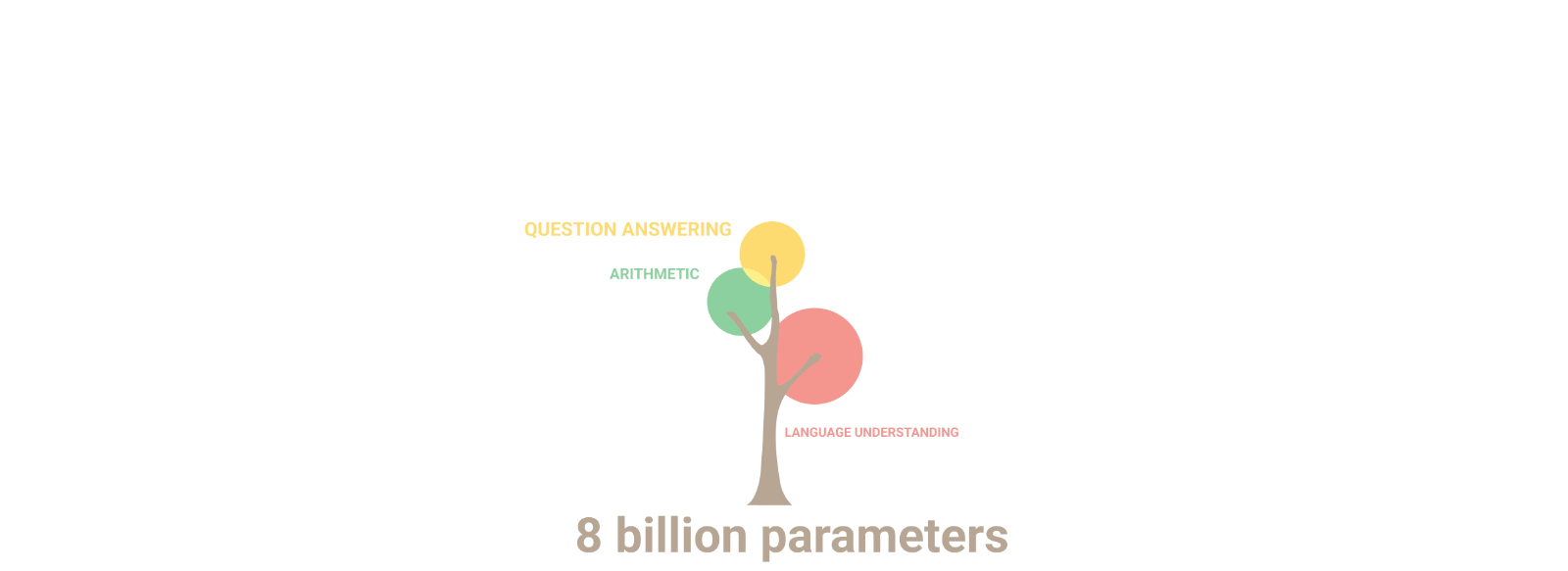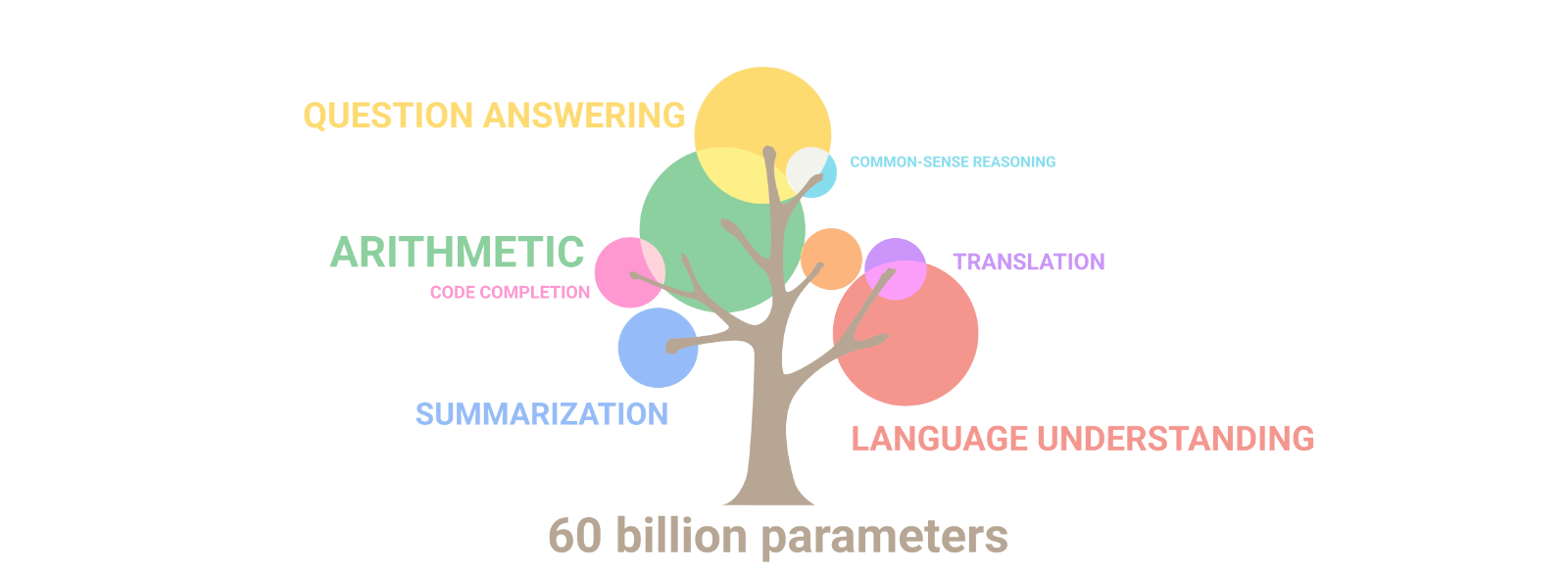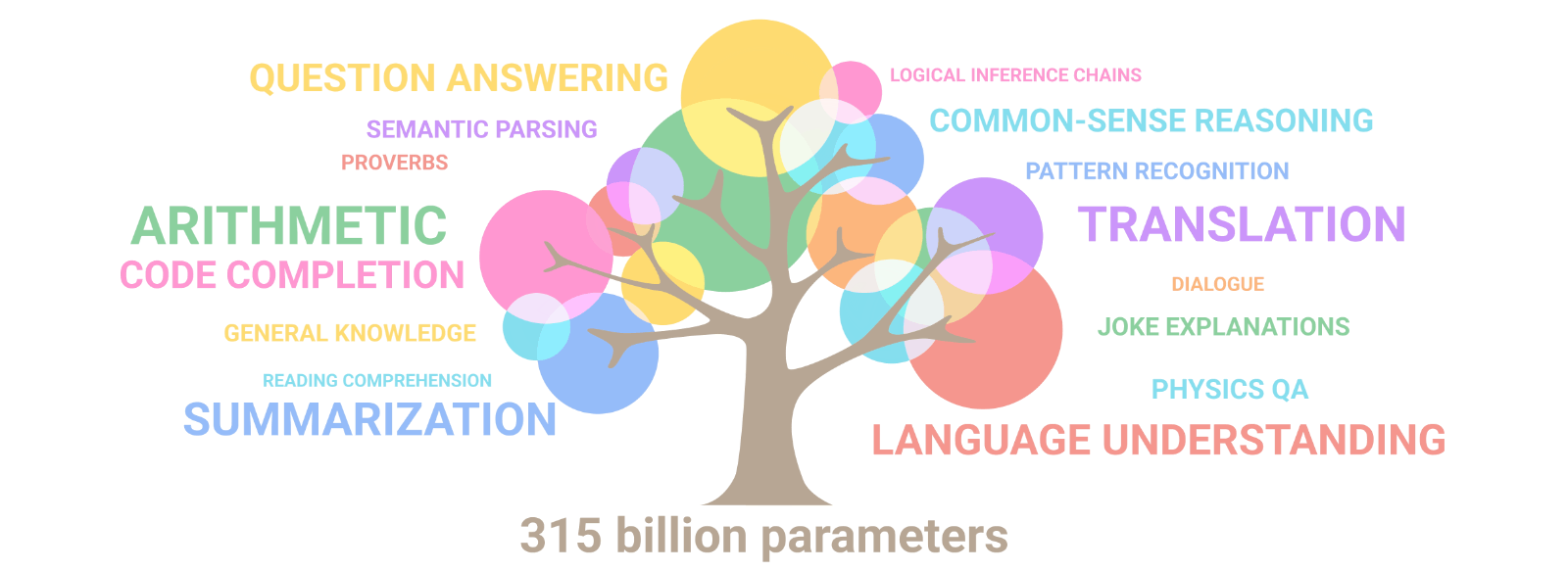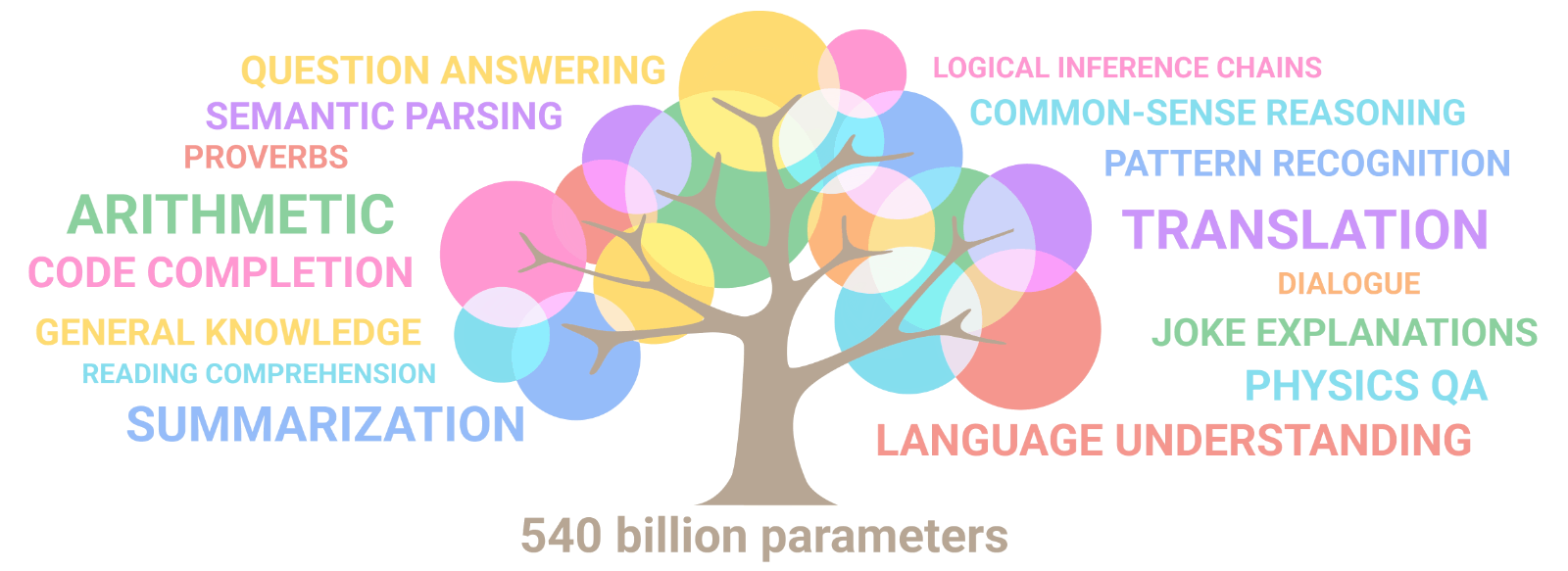
AuroraGPT: General purpose scientific LLM Broadly trained on a general corpora plus scientific {papers, texts, data}
- Explore pathways towards a “Scientific Assistant” model
- Build with international partners (RIKEN, BSC, others)
- Multilingual English, 日本語, French, German, Spanish
- Multimodal: images, tables, equations, proofs, time series, graphs, fields, sequences, etc
Awesome-LLM
🧪 AuroraGPT: Open Science Foundation Model

🌌 Aurora
| Racks | 166 |
| Nodes | 10,624 |
| CPUs | 21,248 |
| GPUs | 63,744 |
| NICs | 84,992 |
| HBM | 8 PB |
| DDR5c | 10 PB |

🍎 Training LLMs
- Want to minimize cost of training
Maximize throughput(?)- Data parallelism takes us only so far (McCandlish et al. 2018)…
- Possible directions:
- Large batch training (?)
- new (second order?) optimizers
- Better tokenization schemes (no tokenizers ?)
- Better data (?)
- Alternative architecture(s) (?)
- Diffusion / flow-matching
- Sub-quadratic attention (state space models, …)
- Large batch training (?)

🍹 Blending Data, Efficiently
- 🐢 Original implementation:
- Slow (serial, single device)
- ~ 1 hr/2T tokens
- 🐇 New implementation:
- Fast! (distributed, asynchronous)
- ~ 2 min/2T tokens
(30x faster !!)

📉 Loss Curve: Training AuroraGPT-7B on 2T Tokens

🔭 LLMs for Science
ChatGPT: explain this image
🧬 MProt-DPO: Scaling Results

3.5B model across ~38,400 GPUs
~ 4 EFLOPS @ Aurora
38,400 XPUs
= 3200 [node] x 12 [XPU / node]🔔 Gordon Bell Finalist1:
🧬 MProt-DPO: Scaling Results
3.5B model

7B model
🚂 Loooooooooong Sequence Lengths

![]()
- Working with Microsoft/DeepSpeed team to enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details


SEQ_LEN for both 25B and 33B models (See: Song et al. (2023))