🎯 AuroraGPT: Goals
AuroraGPT: General purpose scientific LLM
Broadly trained on a general corpora plus scientific {papers, texts, data}
- Explore pathways towards a “Scientific Assistant” model
- Build with international partners (RIKEN, BSC, others)
- Multilingual English, 日本語, French, German, Spanish
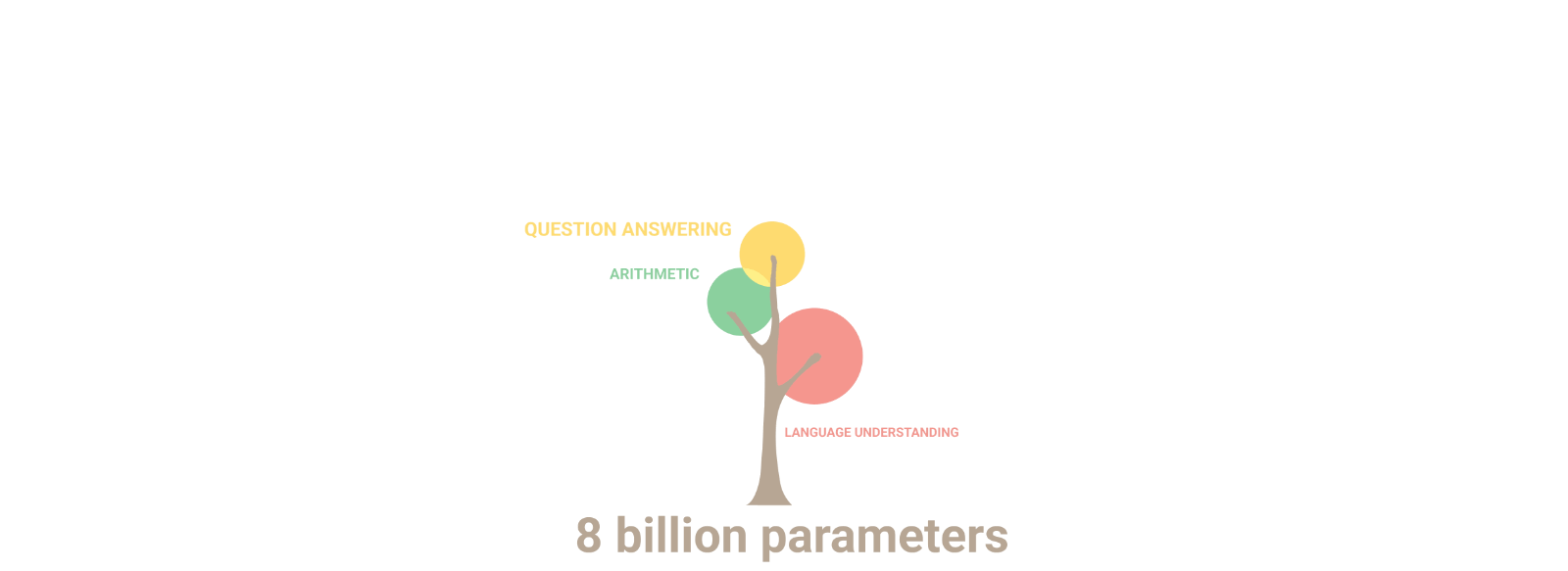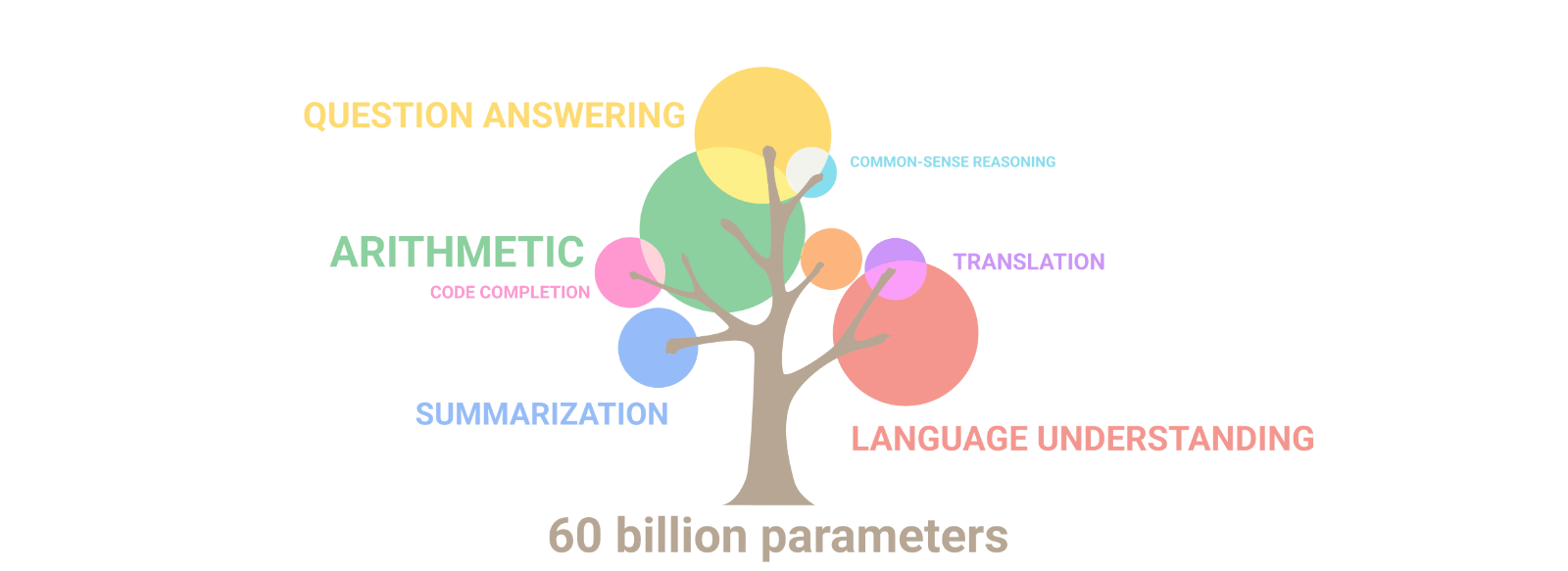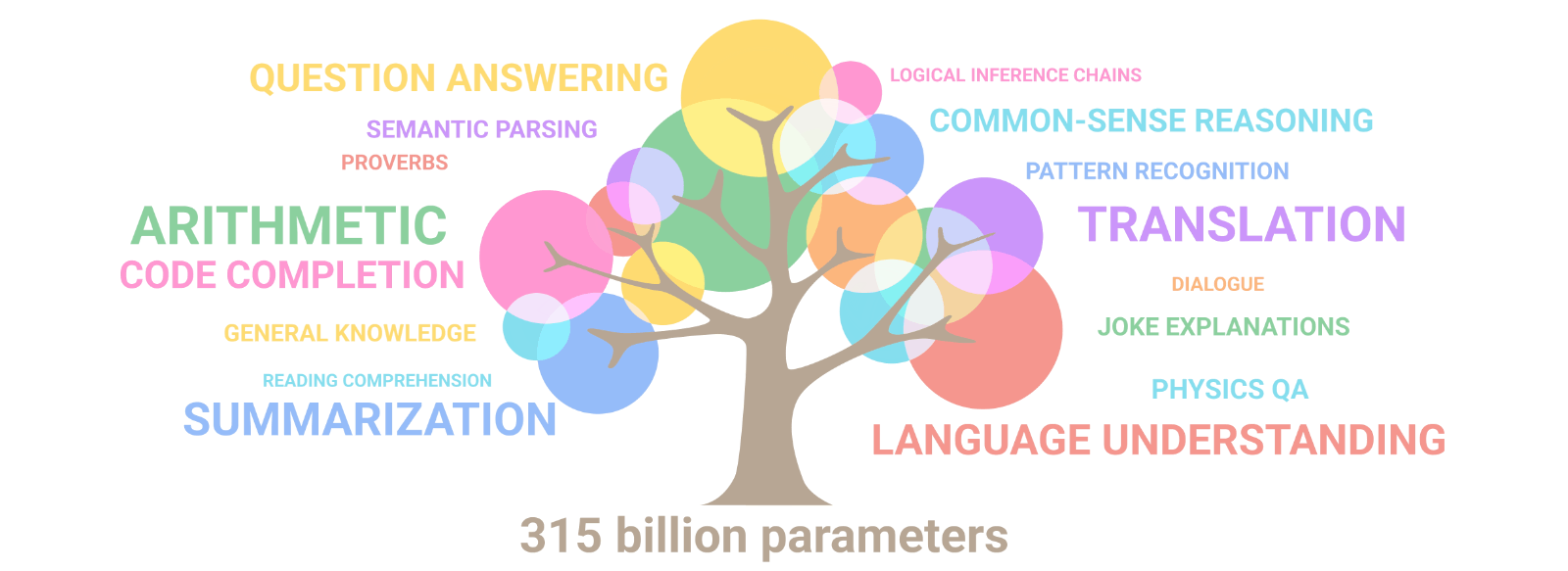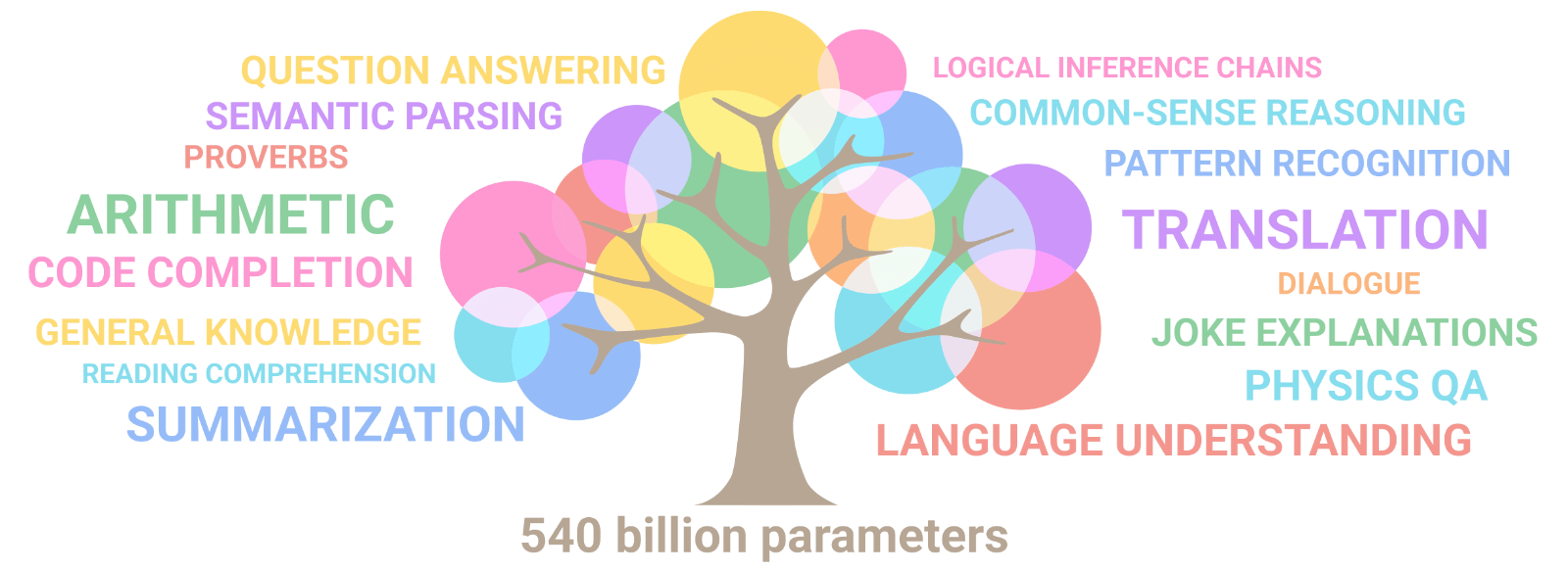
- Multimodal: images, tables, equations, proofs, time series, graphs, fields, sequences, etc
Awesome-LLM

🧪 AuroraGPT: Open Science Foundation Model

🌌 Aurora
| Racks | 166 |
| Nodes | 10,624 |
| CPUs | 21,248 |
| GPUs | 63,744 |
| NICs | 84,992 |
| HBM | 8 PB |
| DDR5c | 10 PB |

🤖 ALCF AI Testbed
- ALCF AI Testbed Systems are in production and available for allocations to the research community
- Significant improvement in time-to-solution and energy-efficiency for diverse AI for science applications.
- NAIRR Pilot
Up to ≈ 25\times throughput improvement for genomic FMs with 6.5\times energy efficiency




👥 Team Leads
Planning






Data

Training


Evaluation



Post


Inference

Comms


Distribution

🚀 Accelerating Dataset Processing: Results
- Original implementation:
- Slow!
- 🐌 ~ 1 hr/2T tokens
-
- Wrote asynchronous, distributed implementation
- significantly improves performance (30x !!)
- 🏎️💨 ~ 2 min/2T tokens

🧬 MProt-DPO: Scaling Results

3.5B Model
🧬 MProt-DPO: Scaling Results
3.5B model

7B model
🚂 Loooooooooong Sequence Lengths

![]()
- Working with Microsoft/DeepSpeed team to enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details


SEQ_LEN for both 25B and 33B models (See: Song et al. (2023))
♻️ Life Cycle of the LLM
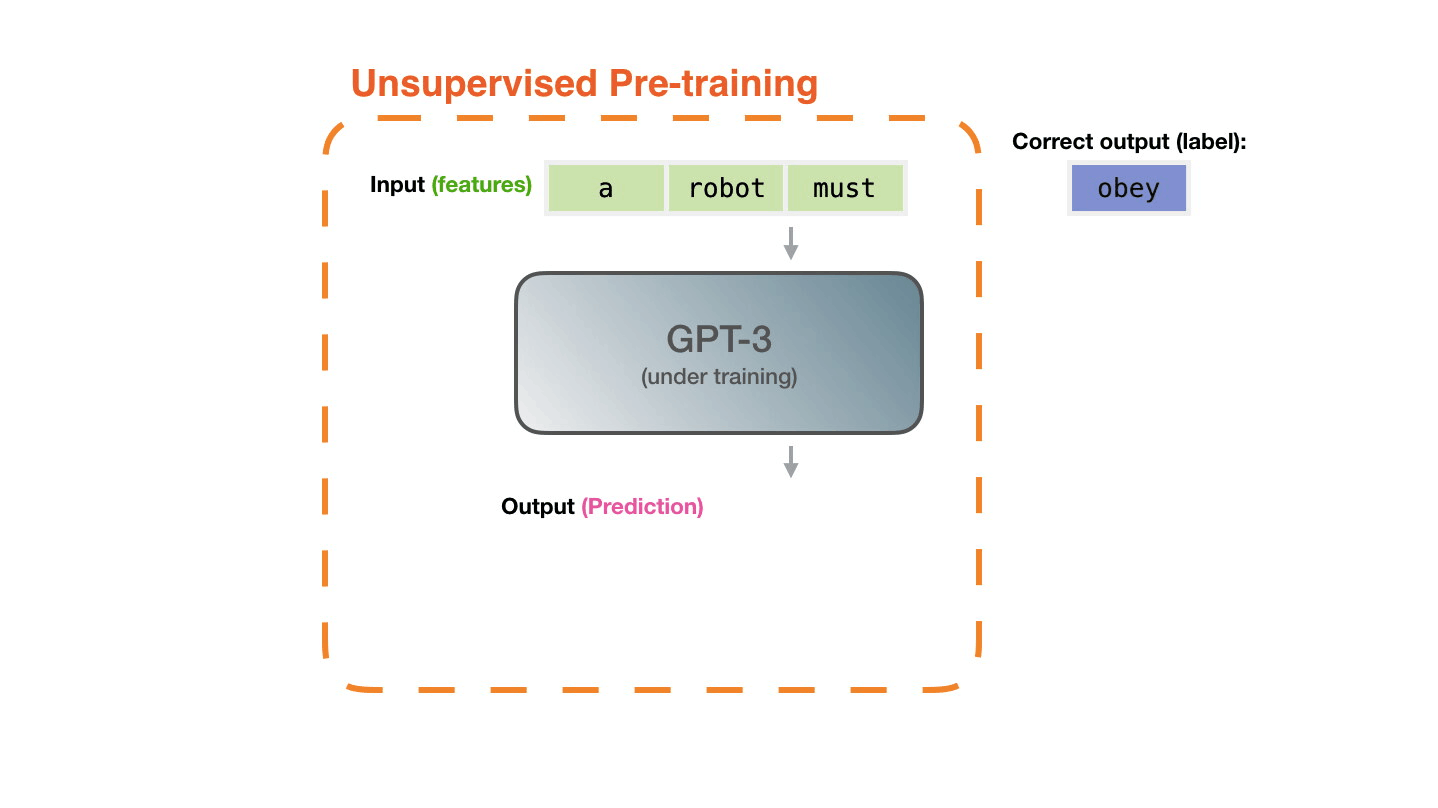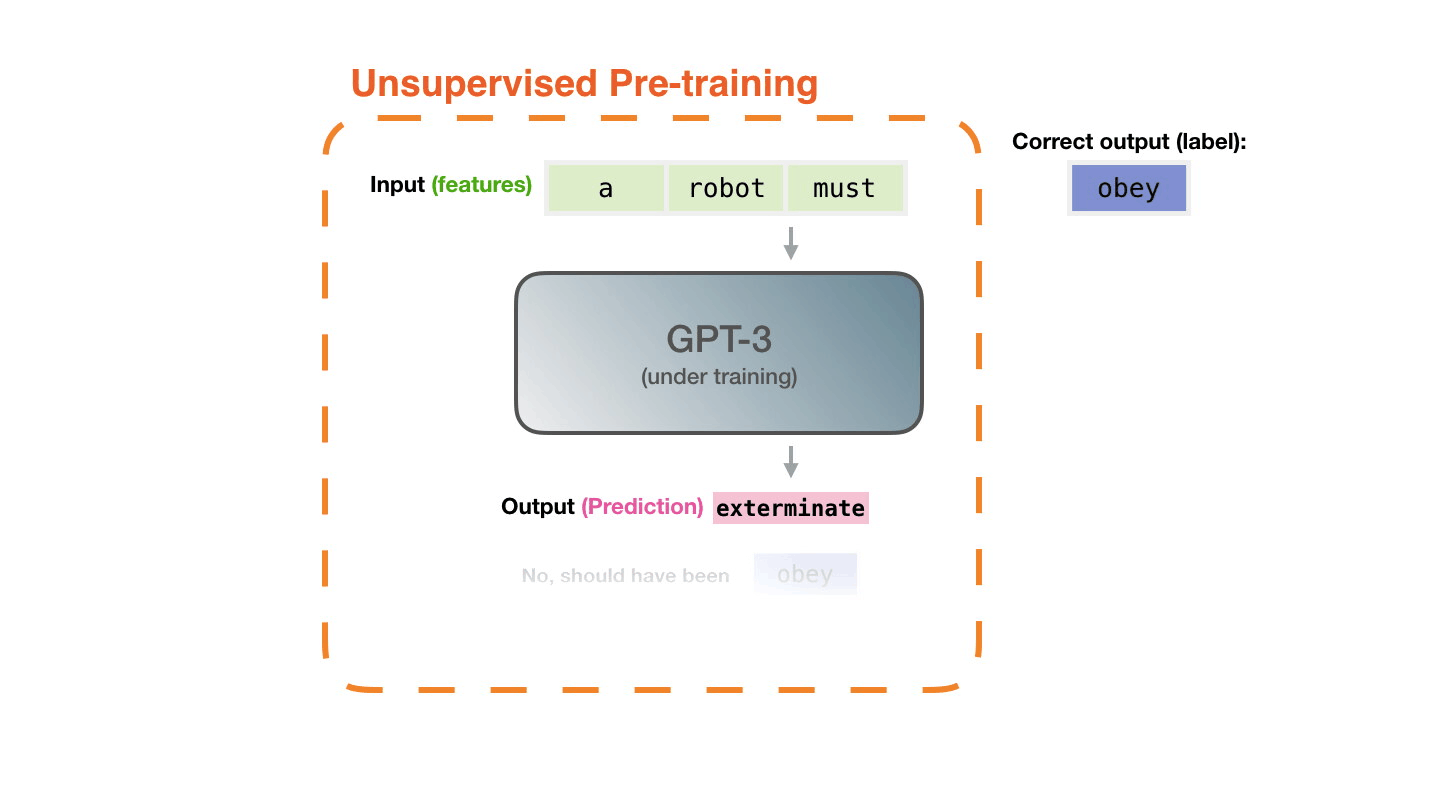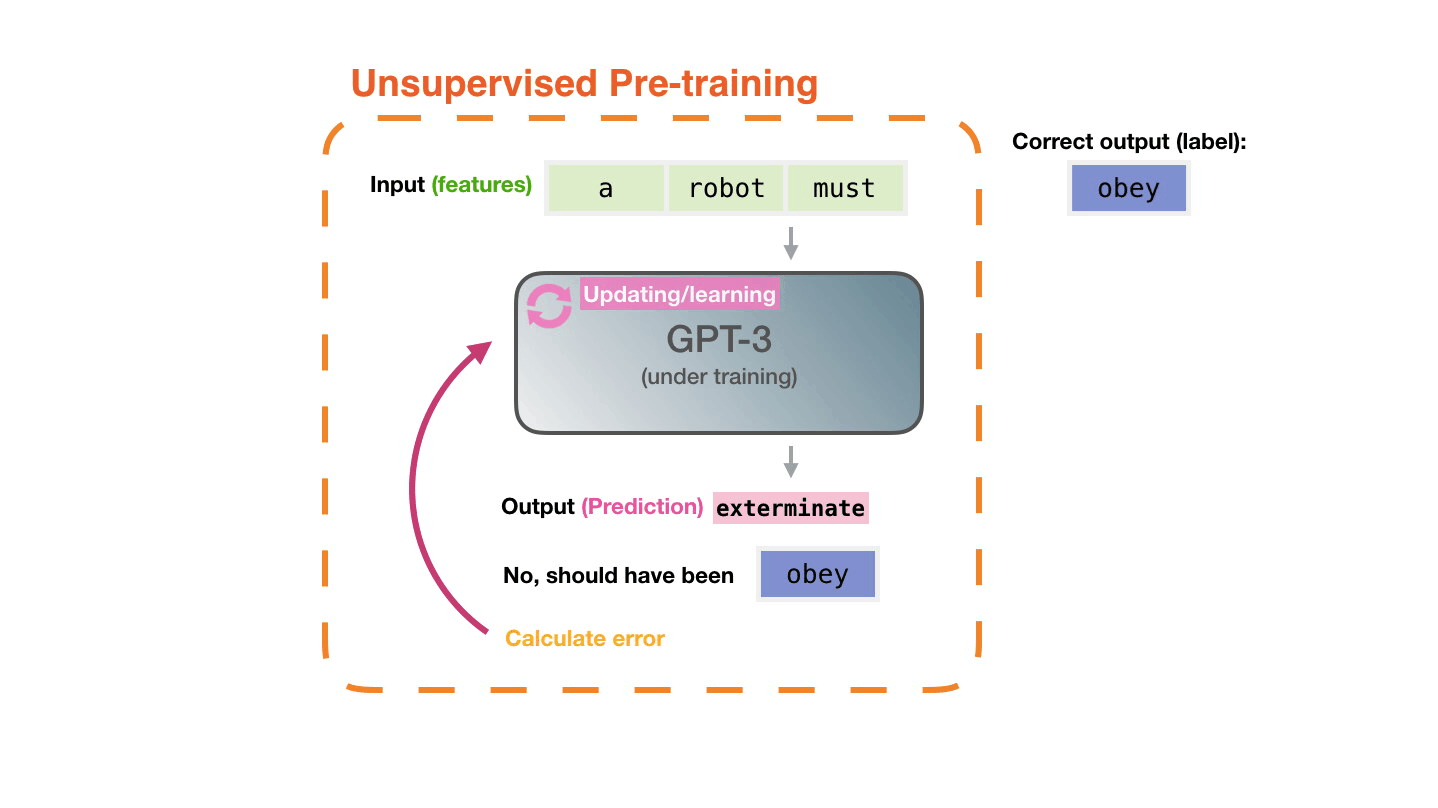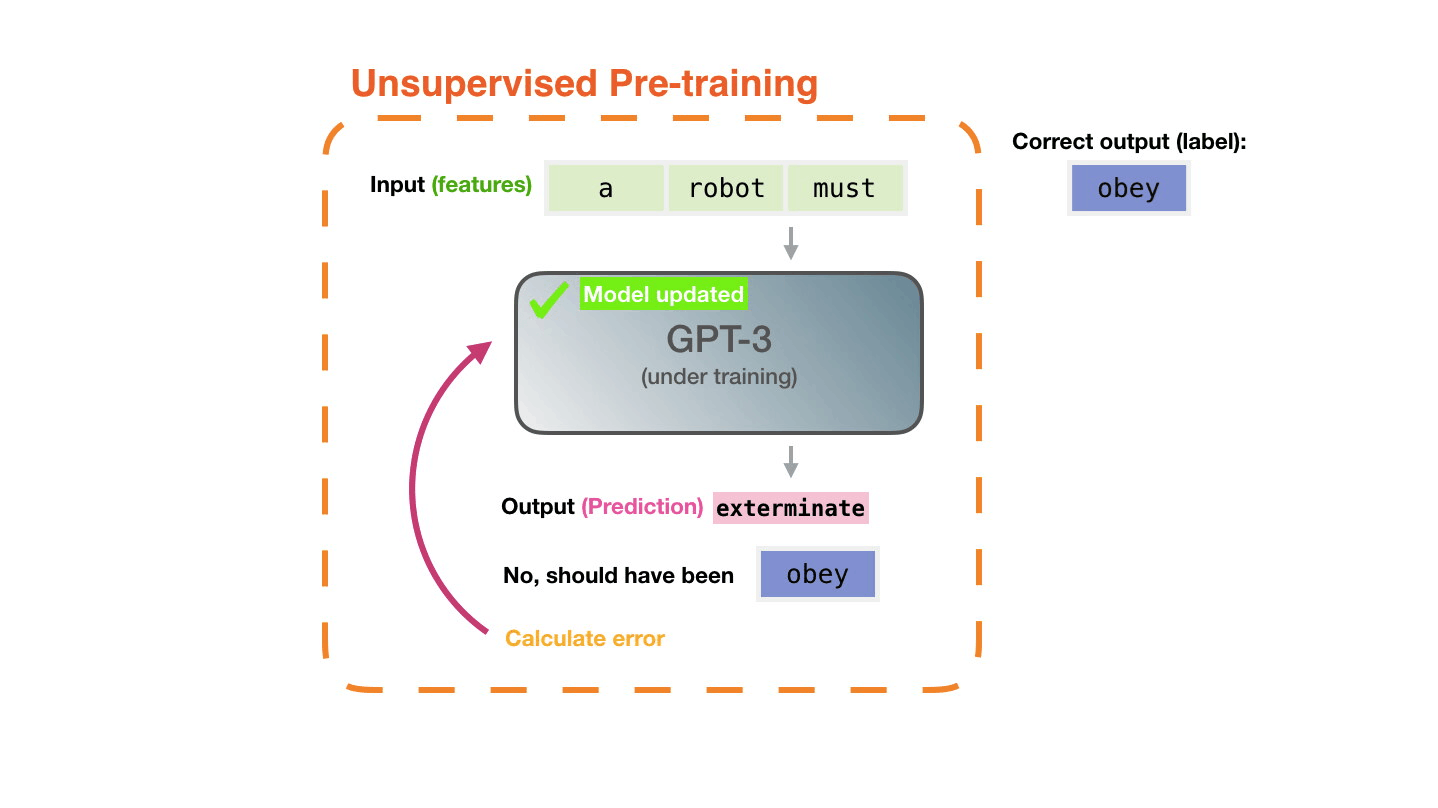
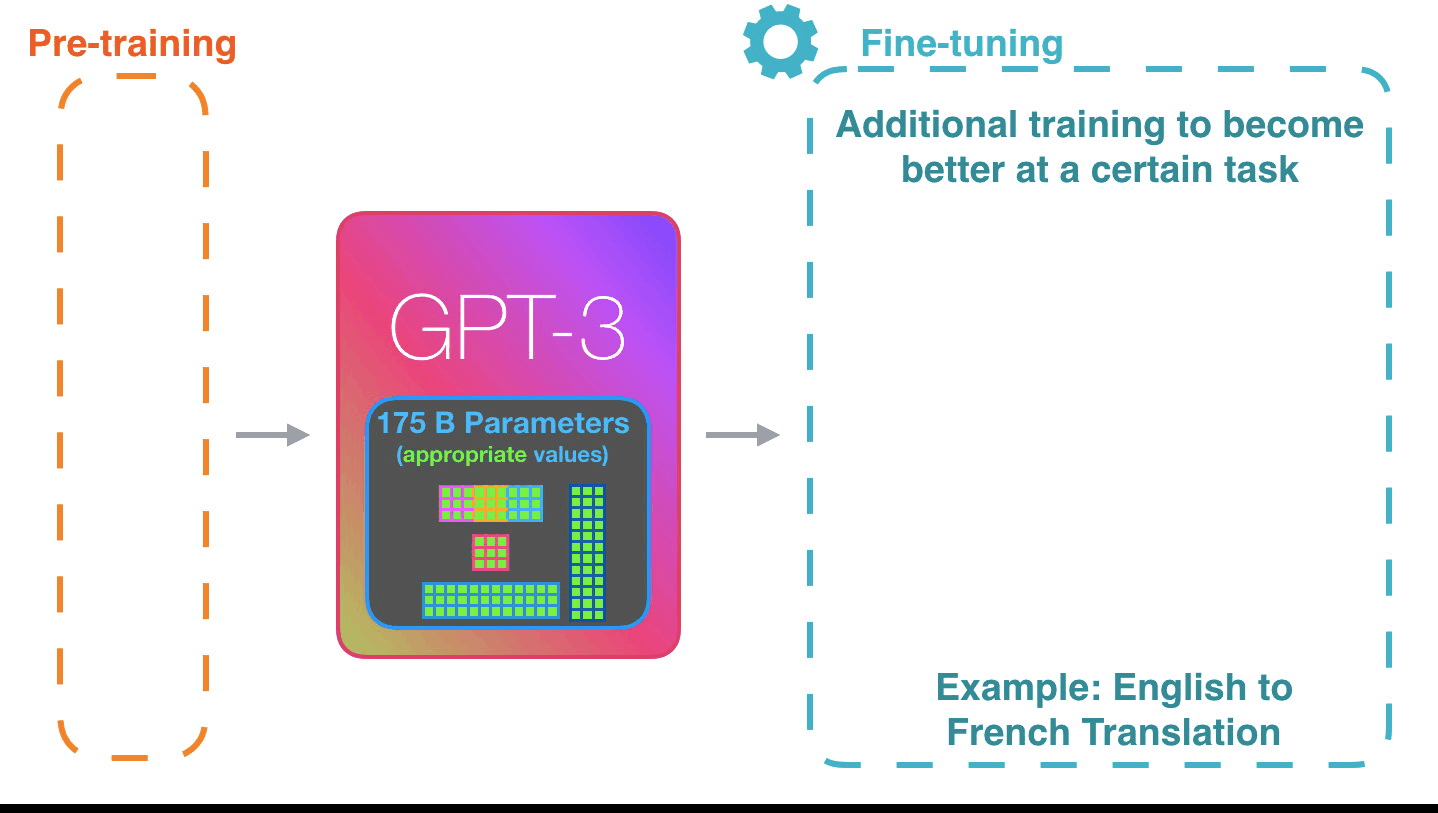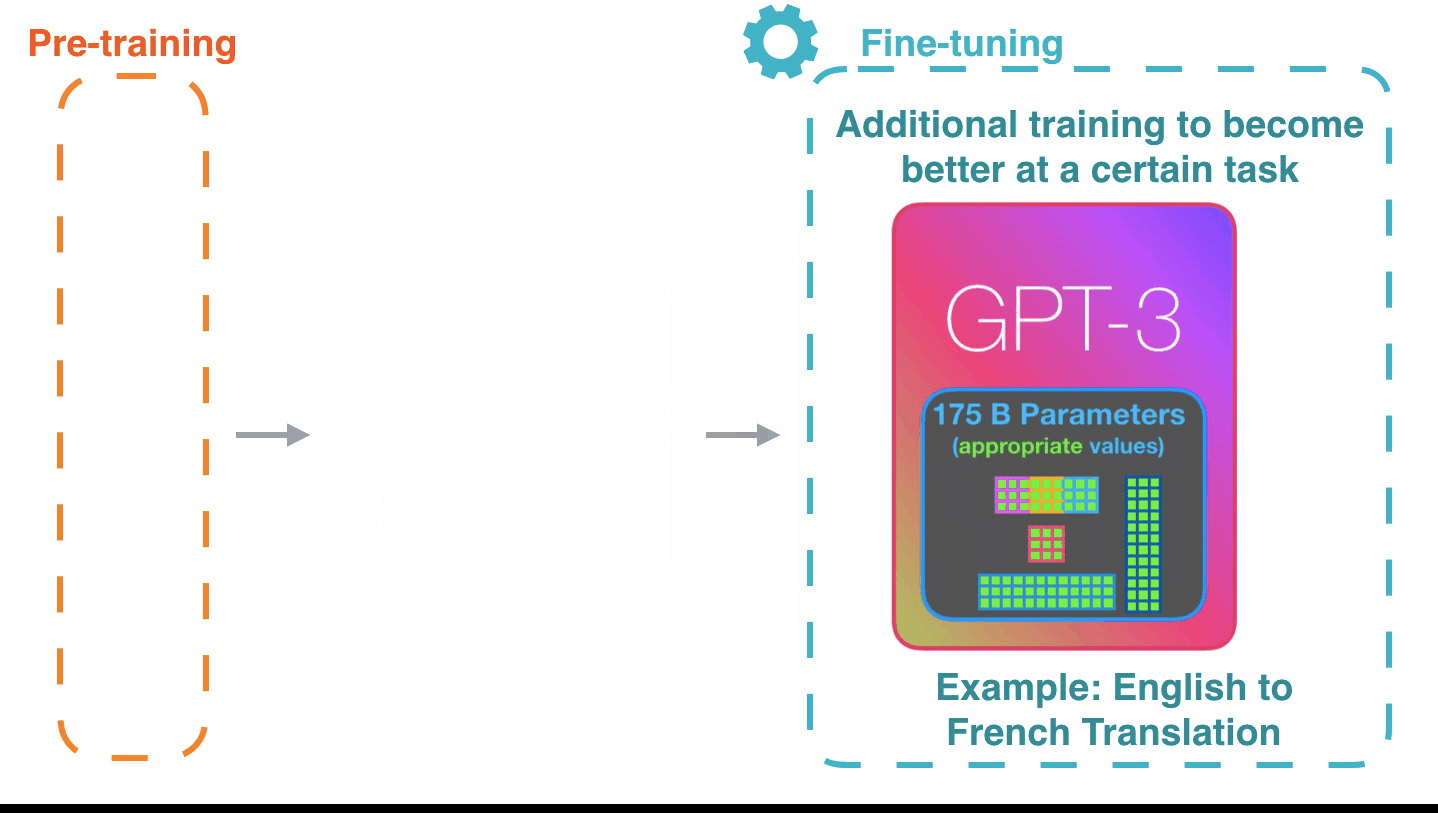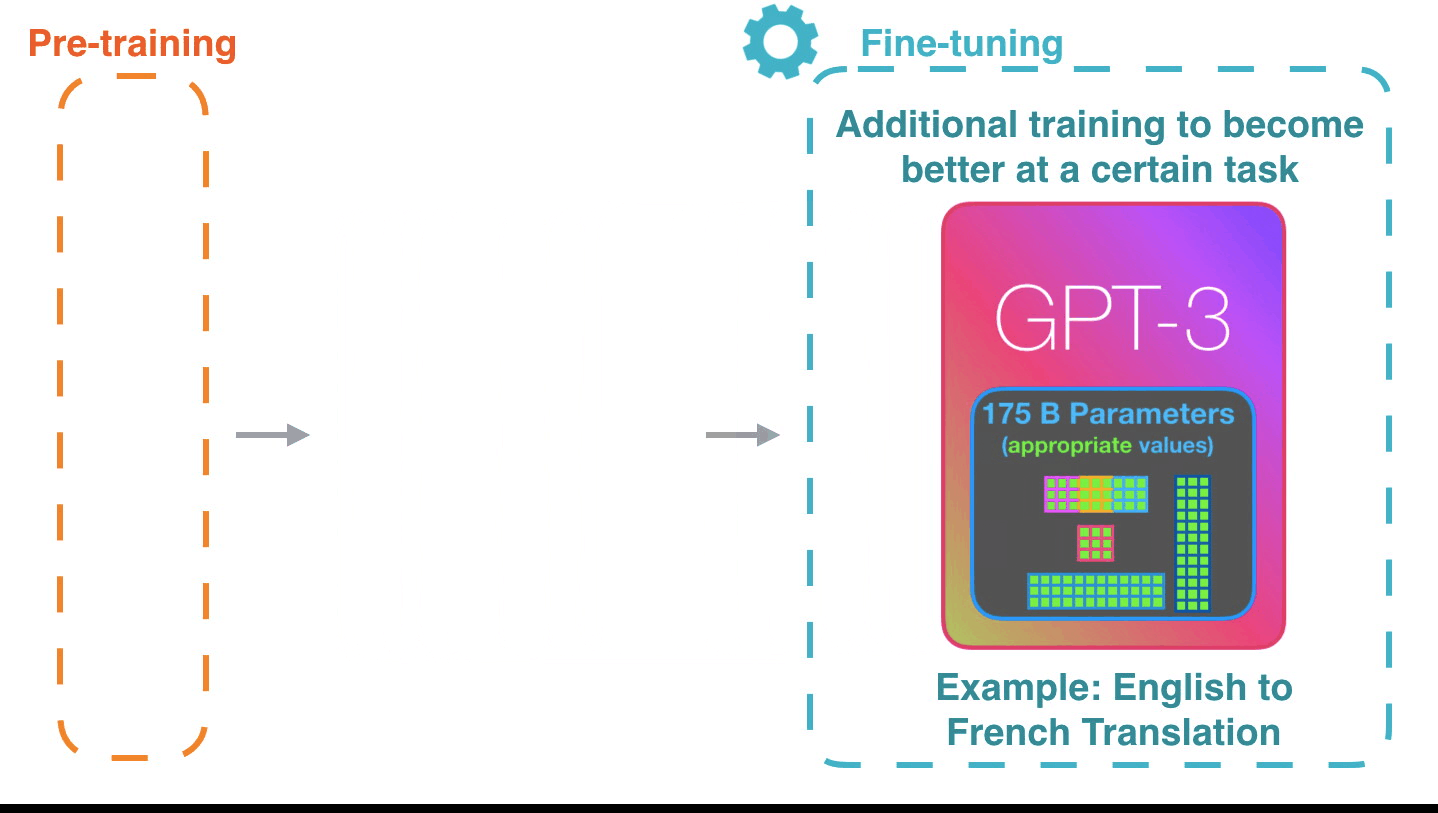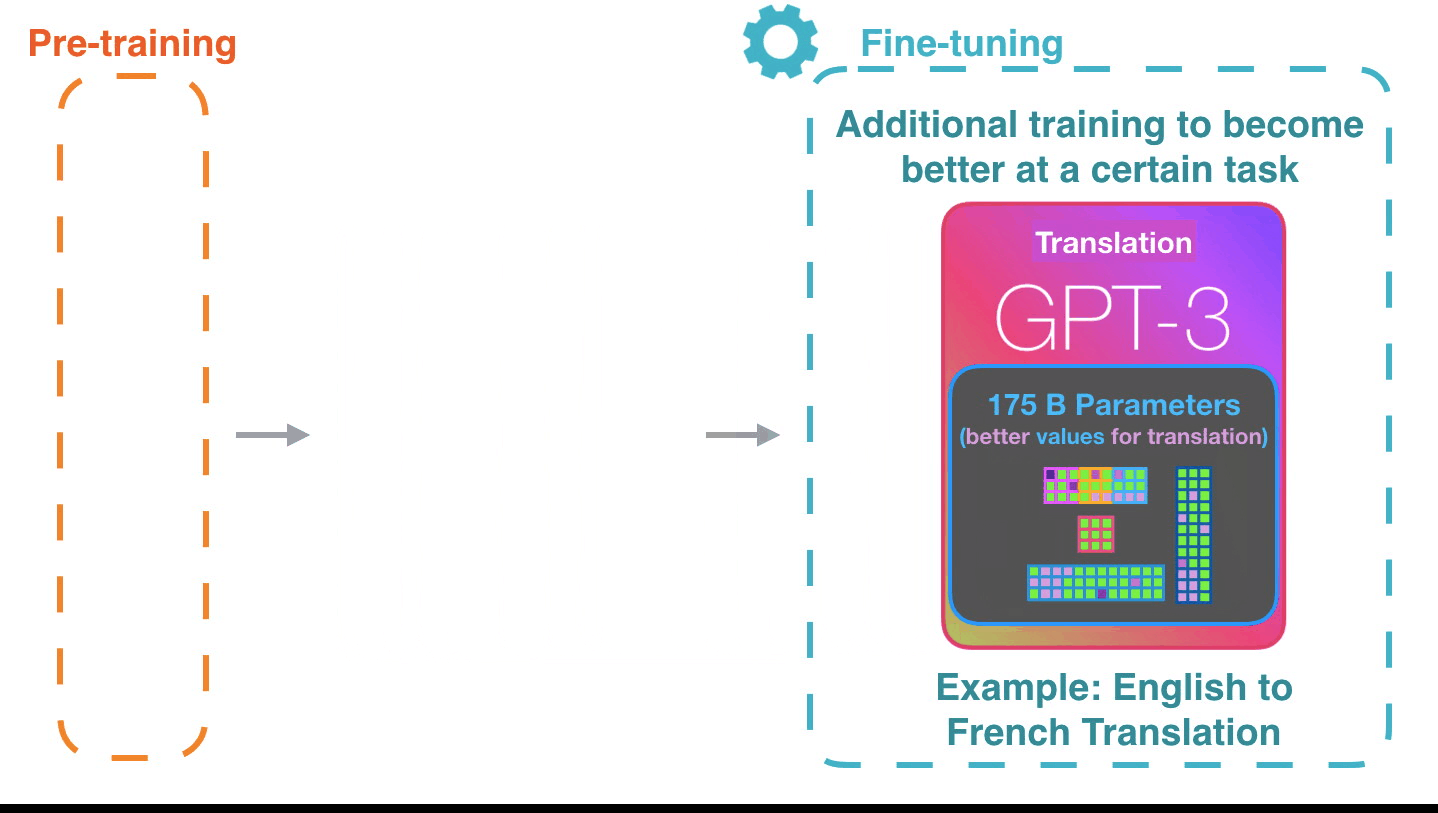
🍎 Training LLMs

