# 🏔️ Spike Skipper
[Sam Foreman](https://samforeman.me)
[](https://orcid.org/0000-0002-9981-0876)
2024-09-17
- [📝 Example](#-example)
- [🧪 Implementation](#-implementation)
- [✅ Sanity Check](#-sanity-check)
- [🔍 Details](#-details)
> [!CAUTION]
>
> ### Details
>
> We describe below our implementation for skipping individual steps
> during training.
## 📝 Example
Suppose we observe a large spike in our loss curve, as shown below:
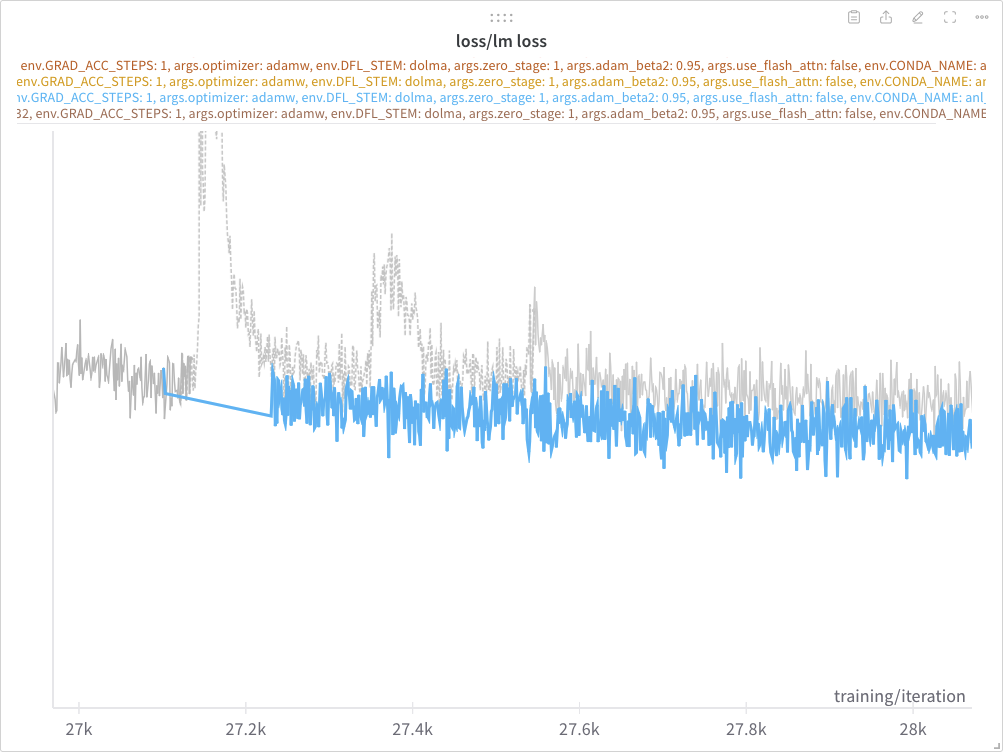
Seemingly, this spike is being caused by a batch of “bad data”. In order
to prevent this “bad data” sample from corrupting our training, we would
like to “skip” that particular training step.
This can be accomplished by passing the keyword argument
`--train-range-to-skip` and specifying the endpoints of the ranges to be
skipped.
e.g., if you would like to skip all steps from `[10, 20]` and from
`[25, 30]`, we would specify:
``` bash
PBS_O_WORKDIR=$(pwd) bash train_aGPT_7B.sh --train-range-to-skip 10 20 25 30
```
## 🧪 Implementation
We discuss below the details of the implementation, and provide some
simple results to confirm things are behaving how we expect.
1. Check if `args.train_range_to_skip is not None`
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1032)\]
- Assert `len(args.train_range_to_skip) % 2 == 0`
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1033-L1037)\]
Must be even since we’re specifying the *endpoint**s*** of
intervals to skip
- Zip these up into pairs
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1038-L1043)\]:
``` python
ranges_to_skip = list(zip(args.train_range_to_skip[::2], args.train_range_to_skip[1::2]))
```
2. If current iteration is in any of these pairs
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1066-L1085)\]
- For each `micro_step` in `range(gradient_accumulation_steps)`,
explicitly:
- draw a new batch of data
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1074-L1076)\]
from our `train_data_iterator`
- immediately discard it (instead of propagating it through the
network)
- Increment
\[[here](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1087-L1094)\]:
- [`DeepSpeedEngine.skipped_steps`](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1090)
- [`DeepSpeedEngine.global_steps`](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1091)
- [`DeepSpeedEngine.micro_steps`](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1092)
- [`DeepSpeedEngine.global_samples`](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1093)
- [`lr_scheduler`](https://github.com/argonne-lcf/Megatron-DeepSpeed/blob/295fcb3d57a40ec513a521aa8814d99a5c8827b8/megatron/training.py#L1094)
## ✅ Sanity Check
In order to confirm things are behaving as expected, we can explicitly
look at the tokens drawn for each step, and ensure that they are the
same regardless of whether or not that iteration was skipped.
- In particular, we see that:
- test 1:
``` bash
[2024-09-16 23:09:09.059118][INFO][training:1083] - iteration=2 [0/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 1858, 3851, 29889, ..., 500, 13, 13],
[ 349, 6156, 1650, ..., 5806, 28557, 3519],
[16554, 304, 1653, ..., 322, 6934, 14722],
[ 4955, 310, 10465, ..., 1438, 3841, 29892]])
[2024-09-16 23:09:09.061999][INFO][training:1083] - iteration=2 [1/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 363, 1302, 16453, ..., 7967, 29891, 484],
[ 367, 766, 4752, ..., 1, 29871, 30143],
[29899, 855, 1503, ..., 3786, 29892, 5100],
[ 465, 1974, 289, ..., 21588, 533, 304]])
```
- test 2:
``` bash
[2024-09-16 22:59:27.752277][INFO][pretrain_gpt_alcf:198] - args.iteration=2:
data['text'][:10]=tensor([[ 1858, 3851, 29889, ..., 500, 13, 13],
[ 349, 6156, 1650, ..., 5806, 28557, 3519],
[16554, 304, 1653, ..., 322, 6934, 14722],
[ 4955, 310, 10465, ..., 1438, 3841, 29892]])
[2024-09-16 22:59:27,755] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:28.568805][INFO][pretrain_gpt_alcf:198] - args.iteration=2:
data['text'][:10]=tensor([[363, 1302, 16453, ..., 7967, 29891, 484],
[ 367, 766, 4752, ..., 1, 29871, 30143],
[29899, 855, 1503, ..., 3786, 29892, 5100],
[ 465, 1974, 289, ..., 21588, 533, 304]])
```
as expected.
### 🔍 Details
- First 4 steps:
tokens:
- Iteration 0:
``` bash
[2024-09-16 22:58:50.168667][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 304, 7344, 5146, ..., 9776, 29914, 26419],
[29889, 13, 4706, ..., 9280, 30004, 13],
[29943, 20774, 29908, ..., 304, 27391, 322],
[ 2645, 445, 29871, ..., 16888, 4656, 10070]])
[2024-09-16 22:58:58.866409][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 2768, 596, 1788, ..., 27274, 393, 30010],
[ 278, 5613, 4192, ..., 362, 310, 1950],
[28038, 29892, 2022, ..., 3160, 278, 2087],
[ 4149, 907, 29888, ..., 29896, 29892, 29896]])
[2024-09-16 22:59:02.043059][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 424, 322, 16232, ..., 366, 748, 467],
[ 13, 462, 1678, ..., 2084, 29892, 3497],
[ 7562, 310, 19320, ..., 8973, 22684, 358],
[ 2089, 3633, 292, ..., 13774, 269, 2375]])
[2024-09-16 22:59:03.456919][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[21411, 322, 3896, ..., 2610, 29889, 319],
[ 8003, 29898, 29900, ..., 12, 6658, 529],
[ 278, 4148, 310, ..., 263, 12212, 282],
[ 5977, 29871, 29906, ..., 15332, 310, 1749]])
[2024-09-16 22:59:04.596630][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 278, 1473, 24987, ..., 263, 2217, 3804],
[ 2973, 263, 18778, ..., 263, 4642, 6673],
[ 309, 323, 804, ..., 1063, 15296, 327],
[ 278, 5864, 322, ..., 9409, 29889, 2178]])
[2024-09-16 22:59:05.486913][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[29892, 13731, 6617, ..., 29871, 29896, 29946],
[ 2892, 1012, 1266, ..., 4036, 7512, 2068],
[ 1473, 1556, 3619, ..., 3762, 338, 263],
[23353, 29918, 2177, ..., 501, 567, 814]])
[2024-09-16 22:59:06.361333][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 5400, 14378, 4768, ..., 2107, 18677, 29889],
[ 9200, 29887, 29914, ..., 293, 24235, 322],
[30143, 4746, 2184, ..., 11891, 29974, 25760],
[19263, 29914, 303, ..., 358, 29889, 13]])
[2024-09-16 22:59:07.230671][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 309, 1306, 681, ..., 310, 23186, 21809],
[29896, 29929, 13, ..., 29871, 29900, 13],
[ 9558, 964, 263, ..., 322, 282, 682],
[ 278, 23904, 21767, ..., 313, 29929, 29889]])
```
- Iteration 1:
``` bash
[2024-09-16 22:59:19.287338][INFO][training_log:661] - iteration= 1/ 635782 | consumed_samples= 768 | consumed_tokens= 3145728 | elapsed_time_per_iteration_ms=29570.0 | learning_rate=9.4372e-09 | global_batch_size=768 | lm loss=11.167250 | loss_scale=1.0 | grad_norm=6.363 | actual_seqlen= 4096 | number_of_skipped_iterations= 0 | number_of_nan_iterations= 0 | samples_per_second=25.972 | tokens_per_gpu_per_second_tgs=4432.597 | [LM]TFLOPs=20.30 | [DS]TFLOPs=26.18 |
[2024-09-16 22:59:19.289582][INFO][utils:207] - [Rank 0] (after 1 iterations) memory (MB) | allocated: 1894.57666015625 | max allocated: 9752.35498046875 | reserved: 11342.0 | max reserved: 11342.0
(min, max) time across ranks (ms):
forward-backward ...............................: (26094.39, 26095.09)
optimizer ......................................: (3407.56, 3409.92)
[2024-09-16 22:59:19.297183][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 1472, 29892, 408, ..., 29892, 1584, 363],
[ 967, 19475, 6593, ..., 8093, 29899, 11249],
[ 1006, 2218, 13326, ..., 2355, 1304, 304],
[29900, 29916, 29947, ..., 353, 1870, 29936]])
[2024-09-16 22:59:20.104352][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 2354, 274, 1041, ..., 29892, 13049, 9098],
[ 8798, 9547, 10353, ..., 303, 3143, 29889],
[ 1373, 4056, 7236, ..., 3186, 297, 5837],
[ 1738, 29920, 7355, ..., 13, 29871, 3776]])
[2024-09-16 22:59:20.977036][INFO][utils:326] - >> building dataset for /flare/Aurora_deployment/AuroraGPT/datasets/dolma/data_v1.7_Llama2Tokenizer/c4-0000_text_document
[2024-09-16 22:59:20.977877][INFO][utils:326] - > building dataset index ...
[2024-09-16 22:59:20.977147][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 2020, 306, 1016, ..., 322, 920, 372],
[ 5921, 1749, 7306, ..., 19252, 297, 5664],
[ 970, 770, 28547, ..., 970, 894, 2577],
[ 1907, 363, 14188, ..., 756, 3646, 287]])
[2024-09-16 22:59:21.851620][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 715, 25392, 3104, ..., 289, 5761, 616],
[ 426, 13, 9651, ..., 9651, 1815, 22603],
[ 7714, 1213, 13, ..., 13, 29876, 457],
[29889, 28663, 1230, ..., 1546, 278, 6586]])
[2024-09-16 22:59:22.720945][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[29929, 13, 13, ..., 10739, 4770, 11277],
[ 4528, 304, 2367, ..., 2501, 385, 4203],
[ 869, 319, 794, ..., 3158, 29889, 3115],
[ 592, 260, 4125, ..., 284, 1135, 18655]])
[2024-09-16 22:59:23.590149][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[14338, 25323, 3321, ..., 5607, 1806, 1164],
[ 322, 278, 15352, ..., 6462, 313, 1552],
[25738, 714, 29889, ..., 29915, 29879, 24842],
[ 5122, 399, 29889, ..., 29947, 7284, 2305]])
[2024-09-16 22:59:24.457646][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 367, 19310, 1891, ..., 2408, 292, 263],
[ 470, 3307, 5713, ..., 568, 2594, 19385],
[29953, 29905, 1631, ..., 1118, 343, 29897],
[10261, 373, 5490, ..., 511, 297, 1760]])
[2024-09-16 22:59:25.326699][INFO][pretrain_gpt_alcf:198] - args.iteration=1: data['text'][:10]=tensor([[ 1006, 326, 29901, ..., 14834, 6694, 9595],
[12058, 5446, 29892, ..., 29889, 8246, 3310],
[ 7483, 310, 278, ..., 402, 9851, 4423],
[ 8041, 813, 322, ..., 3303, 3900, 393]])
```
- Iteration 2:
``` bash
[2024-09-16 22:59:27.744603][INFO][training_log:661] - iteration= 2/ 635782 | consumed_samples= 1536 | consumed_tokens= 6291456 | elapsed_time_per_iteration_ms=8457.2 | learning_rate=1.88744e-08 | global_batch_size=768 | lm loss=11.164009 | loss_scale=1.0 | grad_norm=6.271 | actual_seqlen= 4096 | number_of_skipped_iterations= 0 | number_of_nan_iterations= 0 | samples_per_second=90.810 | tokens_per_gpu_per_second_tgs=15498.234 | [LM]TFLOPs=70.98| [DS]TFLOPs=91.53 |
(min, max) time across ranks (ms):
forward-backward ...............................: (8384.83, 8385.57)
optimizer ......................................: (55.03, 55.61)
[2024-09-16 22:59:27.752277][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 1858, 3851, 29889, ..., 500, 13, 13],
[ 349, 6156, 1650, ..., 5806, 28557, 3519],
[16554, 304, 1653, ..., 322, 6934, 14722],
[ 4955, 310, 10465, ..., 1438, 3841, 29892]])
[2024-09-16 22:59:27,755] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:28.568805][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 363, 1302, 16453, ..., 7967, 29891, 484],
[ 367, 766, 4752, ..., 1, 29871, 30143],
[29899, 855, 1503, ..., 3786, 29892, 5100],
[ 465, 1974, 289, ..., 21588, 533, 304]])
[2024-09-16 22:59:28,571] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:29.440843][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[29889, 13, 4806, ..., 3086, 26040, 9220],
[ 293, 7207, 355, ..., 18131, 520, 1247],
[ 8619, 29889, 29871, ..., 304, 10029, 266],
[ 363, 15202, 29892, ..., 482, 17162, 19104]])
[2024-09-16 22:59:29,443] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:30.313403][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[25561, 411, 278, ..., 297, 2898, 26163],
[22574, 2607, 18134, ..., 13, 4706, 500],
[20190, 24820, 1623, ..., 310, 901, 29892],
[29892, 1951, 4486, ..., 869, 887, 30010]])
[2024-09-16 22:59:30,316] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:31.185339][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 5371, 22417, 29892, ..., 13, 6716, 901],
[ 353, 1565, 29936, ..., 29878, 3567, 7196],
[17296, 338, 1985, ..., 3741, 9089, 422],
[ 694, 13331, 310, ..., 21180, 29892, 607]])
[2024-09-16 22:59:31,188] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:32.057207][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 292, 8818, 267, ..., 29892, 11275, 7407],
[ 1870, 29897, 13, ..., 2697, 29901, 13],
[29913, 338, 263, ..., 29892, 591, 3394],
[ 2253, 472, 1554, ..., 982, 304, 376]])
[2024-09-16 22:59:32,060] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:32.930293][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 391, 2598, 29883, ..., 22629, 346, 440],
[29871, 29896, 29906, ..., 407, 583, 2833],
[ 4262, 1836, 13, ..., 310, 263, 10608],
[ 1199, 411, 24770, ..., 272, 2153, 29889]])
[2024-09-16 22:59:32,932] [INFO] [profiler.py:81:start_profile] Flops profiler started
[2024-09-16 22:59:33.803567][INFO][pretrain_gpt_alcf:198] - args.iteration=2: data['text'][:10]=tensor([[ 620, 20503, 428, ..., 297, 1009, 9443],
[ 950, 25078, 892, ..., 408, 10636, 284],
[ 1012, 2003, 364, ..., 7313, 29912, 19303],
[29906, 29892, 29945, ..., 967, 26414, 472]])
```
- Iteration 3:
``` bash
[2024-09-16 22:59:34.881265][INFO][training_log:661] - iteration= 3/ 635782 | consumed_samples= 2304 | consumed_tokens= 9437184 | elapsed_time_per_iteration_ms=7136.5 | learning_rate=2.83116e-08 | global_batch_size=768 | lm loss=11.164038 | loss_scale=1.0 | grad_norm=6.279 | actual_seqlen= 4096 | number_of_skipped_iterations= 0 | number_of_nan_iterations= 0 | samples_per_second=107.615 | tokens_per_gpu_per_second_tgs=18366.372 | [LM]TFLOPs=84.12 | [DS]TFLOPs=108.46 |
(min, max) time across ranks (ms):
forward-backward ...............................: (7078.48, 7079.28)
optimizer ......................................: (38.62, 43.08)
[2024-09-16 22:59:34.888870][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[ 496, 313, 29941, ..., 1316, 408, 4857],
[29899, 3204, 29889, ..., 1074, 330, 2547],
[29916, 29900, 29946, ..., 18455, 29889, 4002],
[26406, 338, 1641, ..., 670, 1914, 6900]])
[2024-09-16 22:59:35.719630][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[29945, 29900, 867, ..., 7601, 12091, 310],
[ 975, 29871, 29896, ..., 3573, 825, 306],
[29906, 29900, 4638, ..., 29227, 23145, 29892],
[ 278, 14368, 322, ..., 14909, 29936, 25913]])
[2024-09-16 22:59:36.591343][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[ 988, 306, 1033, ..., 437, 408, 1532],
[ 450, 10317, 310, ..., 322, 752, 13036],
[11405, 8020, 29889, ..., 471, 18096, 287],
[ 288, 3594, 19284, ..., 910, 338, 385]])
[2024-09-16 22:59:37.463941][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[ 322, 15151, 29946, ..., 11648, 1497, 29889],
[24233, 362, 467, ..., 4513, 1353, 322],
[ 3311, 13605, 29912, ..., 945, 29899, 4181],
[ 1951, 366, 508, ..., 6589, 491, 777]])
[2024-09-16 22:59:38.343307][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[29889, 29900, 13, ..., 6017, 424, 1711],
[ 297, 5500, 1489, ..., 310, 3802, 7875],
[ 8078, 5314, 515, ..., 373, 278, 6991],
[13763, 6204, 6359, ..., 4706, 2024, 1347]])
[2024-09-16 22:59:39.214871][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[ 13, 4806, 3512, ..., 278, 7824, 6438],
[ 2294, 938, 903, ..., 4537, 3047, 449],
[ 1230, 4123, 767, ..., 310, 963, 21003],
[ 1152, 2319, 10365, ..., 367, 14040, 363]])
[2024-09-16 22:59:40.085368][INFO][utils:326] - >> building dataset for /flare/Aurora_deployment/AuroraGPT/datasets/dolma/data_v1.7_Llama2Tokenizer/tulu_flan-0000_text_document
[2024-09-16 22:59:40.086224][INFO][utils:326] - > building dataset index ...
[2024-09-16 22:59:40.085475][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[27297, 29924, 801, ..., 28947, 29892, 470],
[12542, 5568, 703, ..., 426, 13, 4706],
[ 6907, 800, 322, ..., 29892, 1661, 30304],
[29900, 13630, 293, ..., 26552, 363, 975]])
[2024-09-16 22:59:40.958071][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[ 13, 29946, 29953, ..., 29953, 29945, 29871],
[ 1283, 16578, 1156, ..., 408, 2215, 408],
[29906, 4229, 7671, ..., 13, 1576, 1014],
[ 526, 2898, 304, ..., 471, 4802, 29991]])
```
- Iteration 4:
``` bash
[2024-09-16 22:59:42.028460][INFO][training_log:661] - iteration= 4/ 635782 | consumed_samples= 3072 | consumed_tokens= 12582912 | elapsed_time_per_iteration_ms=7147.0 | learning_rate=3.77488e-08 | global_batch_size=768 | lm loss=11.171233 | loss_scale=1.0 | grad_norm=6.272 | actual_seqlen= 4096 | number_of_skipped_iterations= 0 | number_of_nan_iterations= 0 | samples_per_second=107.458 | tokens_per_gpu_per_second_tgs=18339.524 | [LM]TFLOPs=84.00 | [DS]TFLOPs=108.31 |
(min, max) time across ranks (ms):
forward-backward ...............................: (7091.77, 7092.56)
optimizer ......................................: (39.21, 40.11)
[2024-09-16 22:59:42.035716][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 443, 666, 10170, ..., 278, 619, 7323],
[ 13, 11008, 338, ..., 2472, 363, 22049],
[29871, 13, 29938, ..., 29962, 8521, 29896],
[ 1165, 2280, 304, ..., 306, 471, 2086]])
[2024-09-16 22:59:42.860756][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 304, 679, 304, ..., 1475, 29889, 1570],
[ 2184, 29936, 13, ..., 4706, 970, 1780],
[29872, 352, 29901, ..., 29905, 4915, 29912],
[16809, 304, 1438, ..., 13457, 29889, 13]])
[2024-09-16 22:59:43.731208][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[12015, 29901, 20549, ..., 322, 10752, 17906],
[ 372, 30010, 29879, ..., 29892, 14595, 653],
[18280, 29958, 13, ..., 18884, 736, 6251],
[29889, 13, 13, ..., 599, 373, 17097]])
[2024-09-16 22:59:44.605047][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 3367, 567, 964, ..., 3353, 24870, 2181],
[ 1262, 2609, 367, ..., 29974, 29896, 7570],
[29871, 29941, 29900, ..., 341, 555, 265],
[ 4225, 526, 6041, ..., 1925, 1623, 2748]])
[2024-09-16 22:59:45.479433][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 2283, 10162, 1496, ..., 30656, 30317, 30605],
[29879, 9228, 292, ..., 7968, 29899, 7052],
[ 884, 599, 367, ..., 29892, 278, 6054],
[29879, 411, 278, ..., 367, 5019, 1183]])
[2024-09-16 22:59:46.351707][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 3867, 281, 761, ..., 11949, 338, 4922],
[ 297, 1432, 2586, ..., 5414, 278, 29811],
[29892, 278, 15562, ..., 10296, 310, 394],
[ 1451, 2960, 3505, ..., 657, 14346, 8003]])
[2024-09-16 22:59:47.222016][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 6601, 2874, 414, ..., 302, 317, 7390],
[16415, 297, 5146, ..., 763, 372, 471],
[29941, 29906, 1118, ..., 29900, 29889, 29953],
[ 4893, 304, 4808, ..., 2284, 2164, 18690]])
[2024-09-16 22:59:48.094752][INFO][pretrain_gpt_alcf:198] - args.iteration=4: data['text'][:10]=tensor([[ 901, 310, 2994, ..., 29873, 1641, 766],
[ 304, 1716, 2562, ..., 3489, 304, 367],
[ 1949, 6736, 29871, ..., 29965, 29909, 353],
[ 13, 13, 29930, ..., 16497, 316, 474]])
```
- Skipping steps `[2, 3]`:
tokens:
- Iteration 0:
``` bash
[2024-09-16 23:08:47.749839][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 304, 7344, 5146, ..., 9776, 29914, 26419],
[29889, 13, 4706, ..., 9280, 30004, 13],
[29943, 20774, 29908, ..., 304, 27391, 322],
[ 2645, 445, 29871, ..., 16888, 4656, 10070]])
[2024-09-16 23:08:51.451183][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 2768, 596, 1788, ..., 27274, 393, 30010],
[ 278, 5613, 4192, ..., 362, 310, 1950],
[28038, 29892, 2022, ..., 3160, 278, 2087],
[ 4149, 907, 29888, ..., 29896, 29892, 29896]])
[2024-09-16 23:08:54.073597][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 424, 322, 16232, ..., 366, 748, 467],
[ 13, 462, 1678, ..., 2084, 29892, 3497],
[ 7562, 310, 19320, ..., 8973, 22684, 358],
[ 2089, 3633, 292, ..., 13774, 269, 2375]])
[2024-09-16 23:08:56.212476][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[21411, 322, 3896, ..., 2610, 29889, 319],
[ 8003, 29898, 29900, ..., 12, 6658, 529],
[ 278, 4148, 310, ..., 263, 12212, 282],
[ 5977, 29871, 29906, ..., 15332, 310, 1749]])
[2024-09-16 23:08:57.207940][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 278, 1473, 24987, ..., 263, 2217, 3804],
[ 2973, 263, 18778, ..., 263, 4642, 6673],
[ 309, 323, 804, ..., 1063, 15296, 327],
[ 278, 5864, 322, ..., 9409, 29889, 2178]])
[2024-09-16 23:08:58.083935][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[29892, 13731, 6617, ..., 29871, 29896, 29946],
[ 2892, 1012, 1266, ..., 4036, 7512, 2068],
[ 1473, 1556, 3619, ..., 3762, 338, 263],
[23353, 29918, 2177, ..., 501, 567, 814]])
[2024-09-16 23:08:58.951793][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 5400, 14378, 4768, ..., 2107, 18677, 29889],
[ 9200, 29887, 29914, ..., 293, 24235, 322],
[30143, 4746, 2184, ..., 11891, 29974, 25760],
[19263, 29914, 303, ..., 358, 29889, 13]])
[2024-09-16 23:08:59.820234][INFO][pretrain_gpt_alcf:198] - args.iteration=0: data['text'][:10]=tensor([[ 309, 1306, 681, ..., 310, 23186, 21809],
[29896, 29929, 13, ..., 29871, 29900, 13],
[ 9558, 964, 263, ..., 322, 282, 682],
[ 278, 23904, 21767, ..., 313, 29929, 29889]])
```
- Iteration 1:
``` bash
[2024-09-16 23:09:08.943867][INFO][training_log:661] - iteration= 1/ 635782 | consumed_samples= 768 | consumed_tokens= 3145728 | elapsed_time_per_iteration_ms=21224.4 | learning_rate=9.4372e-09 | global_batch_size=768 | lm loss=11.167250 | loss_scale=1.0 | grad_norm=6.363 | actual_seqlen= 4096 | number_of_skipped_iterations= 0 | number_of_nan_iterations= 0 | samples_per_second=36.185 | tokens_per_gpu_per_second_tgs=6175.523 | [LM]TFLOPs=28.29 | [DS]TFLOPs=36.47 |
[2024-09-16 23:09:08.953432][INFO][training:1083] - iteration=1 [0/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 1472, 29892, 408, ..., 29892, 1584, 363],
[ 967, 19475, 6593, ..., 8093, 29899, 11249],
[ 1006, 2218, 13326, ..., 2355, 1304, 304],
[29900, 29916, 29947, ..., 353, 1870, 29936]])
[2024-09-16 23:09:08.957524][INFO][training:1083] - iteration=1 [1/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 2354, 274, 1041, ..., 29892, 13049, 9098],
[ 8798, 9547, 10353, ..., 303, 3143, 29889],
[ 1373, 4056, 7236, ..., 3186, 297, 5837],
[ 1738, 29920, 7355, ..., 13, 29871, 3776]])
[2024-09-16 23:09:08.966648][INFO][training:1083] - iteration=1 [2/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 2020, 306, 1016, ..., 322, 920, 372],
[ 5921, 1749, 7306, ..., 19252, 297, 5664],
[ 970, 770, 28547, ..., 970, 894, 2577],
[ 1907, 363, 14188, ..., 756, 3646, 287]])
[2024-09-16 23:09:08.969989][INFO][training:1083] - iteration=1 [3/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 715, 25392, 3104, ..., 289, 5761, 616],
[ 426, 13, 9651, ..., 9651, 1815, 22603],
[ 7714, 1213, 13, ..., 13, 29876, 457],
[29889, 28663, 1230, ..., 1546, 278, 6586]])
[2024-09-16 23:09:08.990736][INFO][training:1083] - iteration=1 [4/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[29929, 13, 13, ..., 10739, 4770, 11277],
[ 4528, 304, 2367, ..., 2501, 385, 4203],
[ 869, 319, 794, ..., 3158, 29889, 3115],
[ 592, 260, 4125, ..., 284, 1135, 18655]])
[2024-09-16 23:09:08.993101][INFO][training:1083] - iteration=1 [5/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[14338, 25323, 3321, ..., 5607, 1806, 1164],
[ 322, 278, 15352, ..., 6462, 313, 1552],
[25738, 714, 29889, ..., 29915, 29879, 24842],
[ 5122, 399, 29889, ..., 29947, 7284, 2305]])
[2024-09-16 23:09:09.036896][INFO][training:1083] - iteration=1 [6/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 367, 19310, 1891, ..., 2408, 292, 263],
[ 470, 3307, 5713, ..., 568, 2594, 19385],
[29953, 29905, 1631, ..., 1118, 343, 29897],
[10261, 373, 5490, ..., 511, 297, 1760]])
[2024-09-16 23:09:09.039401][INFO][training:1083] - iteration=1 [7/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 1006, 326, 29901, ..., 14834, 6694, 9595],
[12058, 5446, 29892, ..., 29889, 8246, 3310],
[ 7483, 310, 278, ..., 402, 9851, 4423],
[ 8041, 813, 322, ..., 3303, 3900, 393]])
```
- Iteration 2:
``` bash
[2024-09-16 23:09:09.050766][INFO][training_log:661] - iteration= 2/ 635782 | consumed_samples= 1536 | consumed_tokens= 6291456 | elapsed_time_per_iteration_ms=106.8 | learning_rate=1.88744e-08 | global_batch_size= 768 | loss_scale=1.0 | grad_norm=6.363 | actual_seqlen= 4096 | number_of_skipped_iterations= 1 | number_of_nan_iterations= 0 | samples_per_second=7190.781 | tokens_per_gpu_per_second_tgs=1227226.651 | [LM]TFLOPs=5620.92 | [DS]TFLOPs=7247.49 |
[2024-09-16 23:09:09.055864][INFO][training:1069] - Caught 3 in 'ranges_to_skip', skipping!
[2024-09-16 23:09:09.057929][INFO][training:1082] - torch.Size([4, 4097]), len(train_data_iterator)=490723200
[2024-09-16 23:09:09.059118][INFO][training:1083] - iteration=2 [0/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 1858, 3851, 29889, ..., 500, 13, 13],
[ 349, 6156, 1650, ..., 5806, 28557, 3519],
[16554, 304, 1653, ..., 322, 6934, 14722],
[ 4955, 310, 10465, ..., 1438, 3841, 29892]])
[2024-09-16 23:09:09.061999][INFO][training:1083] - iteration=2 [1/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 363, 1302, 16453, ..., 7967, 29891, 484],
[ 367, 766, 4752, ..., 1, 29871, 30143],
[29899, 855, 1503, ..., 3786, 29892, 5100],
[ 465, 1974, 289, ..., 21588, 533, 304]])
[2024-09-16 23:09:09.065494][INFO][training:1083] - iteration=2 [2/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[29889, 13, 4806, ..., 3086, 26040, 9220],
[ 293, 7207, 355, ..., 18131, 520, 1247],
[ 8619, 29889, 29871, ..., 304, 10029, 266],
[ 363, 15202, 29892, ..., 482, 17162, 19104]])
[2024-09-16 23:09:09.069035][INFO][training:1083] - iteration=2 [3/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[25561, 411, 278, ..., 297, 2898, 26163],
[22574, 2607, 18134, ..., 13, 4706, 500],
[20190, 24820, 1623, ..., 310, 901, 29892],
[29892, 1951, 4486, ..., 869, 887, 30010]])
[2024-09-16 23:09:09.072577][INFO][training:1083] - iteration=2 [4/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 5371, 22417, 29892, ..., 13, 6716, 901],
[ 353, 1565, 29936, ..., 29878, 3567, 7196],
[17296, 338, 1985, ..., 3741, 9089, 422],
[ 694, 13331, 310, ..., 21180, 29892, 607]])
[2024-09-16 23:09:09.075789][INFO][training:1083] - iteration=2 [5/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 292, 8818, 267, ..., 29892, 11275, 7407],
[ 1870, 29897, 13, ..., 2697, 29901, 13],
[29913, 338, 263, ..., 29892, 591, 3394],
[ 2253, 472, 1554, ..., 982, 304, 376]])
[2024-09-16 23:09:09.079052][INFO][training:1083] - iteration=2 [6/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 391, 2598, 29883, ..., 22629, 346, 440],
[29871, 29896, 29906, ..., 407, 583, 2833],
[ 4262, 1836, 13, ..., 310, 263, 10608],
[ 1199, 411, 24770, ..., 272, 2153, 29889]])
[2024-09-16 23:09:09.082739][INFO][training:1083] - iteration=2 [7/8]: (torch.Size([4, 4097]))
_tokens[:10]=tensor([[ 620, 20503, 428, ..., 297, 1009, 9443],
[ 950, 25078, 892, ..., 408, 10636, 284],
[ 1012, 2003, 364, ..., 7313, 29912, 19303],
[29906, 29892, 29945, ..., 967, 26414, 472]])
```
- Iteration 3:
``` bash
[2024-09-16 23:09:09.135651][INFO][training_log:661] - iteration= 3/ 635782 | consumed_samples= 2304 | consumed_tokens= 9437184 | elapsed_time_per_iteration_ms=84.7 | learning_rate=2.83116e-08 | global_batch_size= 768 | loss_scale=1.0 | grad_norm=6.363 | actual_seqlen= 4096 | number_of_skipped_iterations= 1 | number_of_nan_iterations= 0 | samples_per_second=9070.783 | tokens_per_gpu_per_second_tgs=1548080.271 | [LM]TFLOPs=7090.49 | [DS]TFLOPs=9142.31 |
[2024-09-16 23:09:09.143511][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[496, 313, 29941, ..., 1316, 408, 4857],
[29899, 3204, 29889, ..., 1074, 330, 2547],
[29916, 29900, 29946, ..., 18455, 29889, 4002],
[26406, 338, 1641, ..., 670, 1914, 6900]])
[2024-09-16 23:09:09.971988][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[29945, 29900, 867, ..., 7601, 12091, 310],
[ 975, 29871, 29896, ..., 3573, 825, 306],
[29906, 29900, 4638, ..., 29227, 23145, 29892],
[ 278, 14368, 322, ..., 14909, 29936, 25913]])
[2024-09-16 23:09:10.843966][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[988, 306, 1033, ..., 437, 408, 1532],
[ 450, 10317, 310, ..., 322, 752, 13036],
[11405, 8020, 29889, ..., 471, 18096, 287],
[ 288, 3594, 19284, ..., 910, 338, 385]])
[2024-09-16 23:09:11.715513][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[322, 15151, 29946, ..., 11648, 1497, 29889],
[24233, 362, 467, ..., 4513, 1353, 322],
[ 3311, 13605, 29912, ..., 945, 29899, 4181],
[ 1951, 366, 508, ..., 6589, 491, 777]])
[2024-09-16 23:09:12.584136][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[29889, 29900, 13, ..., 6017, 424, 1711],
[ 297, 5500, 1489, ..., 310, 3802, 7875],
[ 8078, 5314, 515, ..., 373, 278, 6991],
[13763, 6204, 6359, ..., 4706, 2024, 1347]])
[2024-09-16 23:09:13.450767][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[13, 4806, 3512, ..., 278, 7824, 6438],
[ 2294, 938, 903, ..., 4537, 3047, 449],
[ 1230, 4123, 767, ..., 310, 963, 21003],
[ 1152, 2319, 10365, ..., 367, 14040, 363]])
[2024-09-16 23:09:14.317517][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[27297, 29924, 801, ..., 28947, 29892, 470],
[12542, 5568, 703, ..., 426, 13, 4706],
[ 6907, 800, 322, ..., 29892, 1661, 30304],
[29900, 13630, 293, ..., 26552, 363, 975]])
[2024-09-16 23:09:15.187191][INFO][pretrain_gpt_alcf:198] - args.iteration=3: data['text'][:10]=tensor([[13, 29946, 29953, ..., 29953, 29945, 29871],
[ 1283, 16578, 1156, ..., 408, 2215, 408],
[29906, 4229, 7671, ..., 13, 1576, 1014],
[ 526, 2898, 304, ..., 471, 4802, 29991]])
```